DeepSeek 轉 Word:數學公式、程式碼與中文匯出 2026
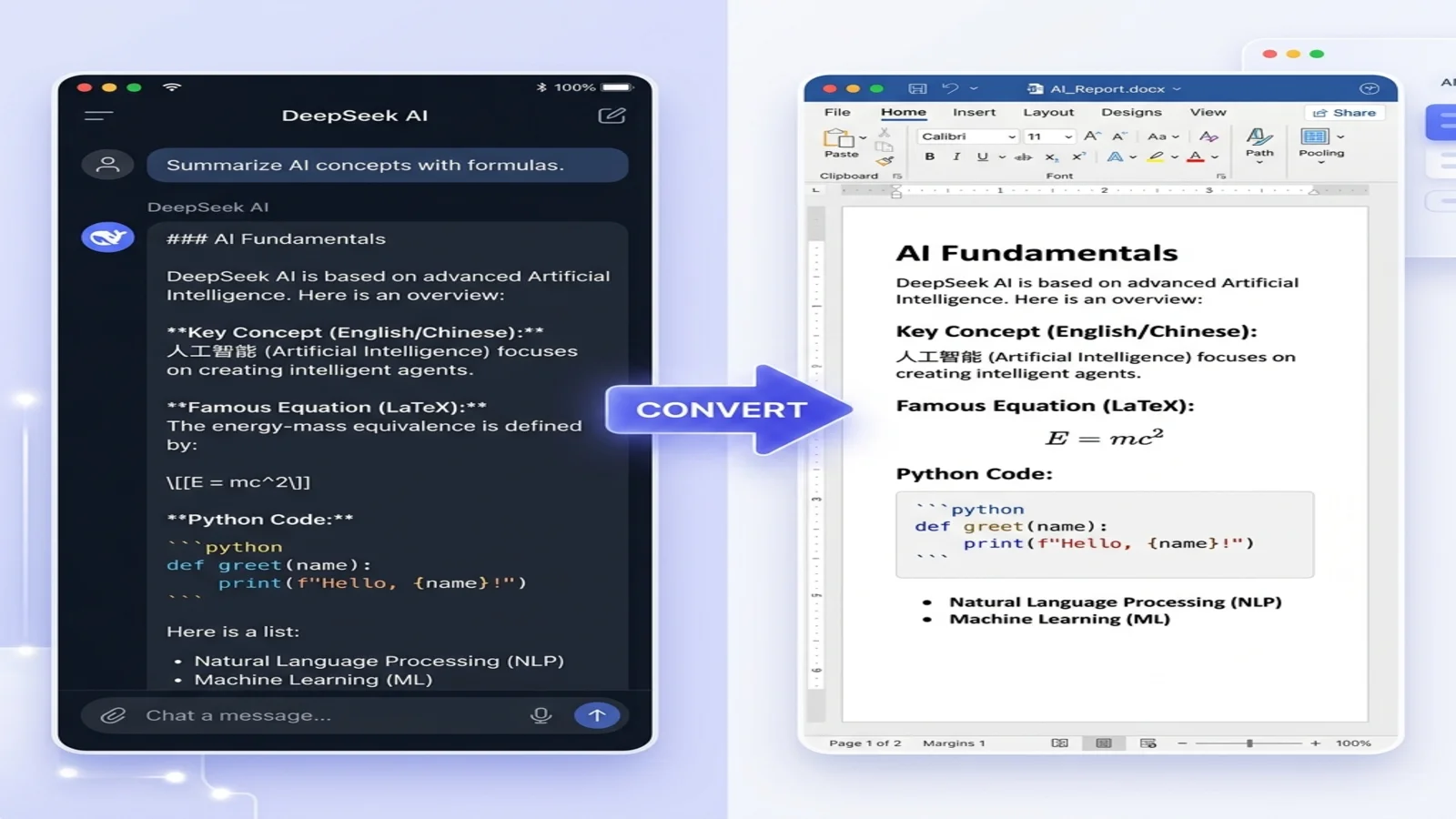
你請 DeepSeek 寫了一份帶數學推導與中英對照說明的研究筆記。對話視窗裡看起來相當漂亮。然後你把它貼進 Word,眼看著它崩掉:LaTeX 公式變成一堆 $$ 符號,中文字元變成空白方框,程式碼區塊的縮排消失得無影無蹤。手動清了二十分鐘之後,你開始納悶——都 2026 年了,這件事怎麼還這麼難。
解決辦法不是再裝一個排版外掛,而是從源頭改掉 DeepSeek 給你的格式。請 DeepSeek 輸出 Markdown,再把這份 Markdown 直接轉成 Word——公式保持可編輯,中文保持清晰,程式碼保持格式。
為什麼 Markdown 工作流更勝一籌
把 DeepSeek 輸出直接貼進 Word,和讓它經過 Markdown 走一遍,結果天差地別——尤其是對 DeepSeek 擅長的數學、程式碼與雙語內容而言。兩種方式對比如下:
| 面向 | 直接複製貼上 | Markdown 工作流 |
|---|---|---|
| 整理工作量 | 每次貼上後都要手動修 | 轉換後下載即可——無需整理 |
| LaTeX 公式 | 以 $$E=mc^2$$ 原文文字貼出 | Word 原生、可編輯公式 |
| 中文字元 | 經常變成空白方框(□□□) | 借助字型回退正確渲染 |
| Python 程式碼區塊 | 縮排遺失、沒有等寬字型 | 等寬字型,縮排保留 |
| 表格 | 框線錯亂 | 乾淨的 Word 原生表格 |
這份指南會帶你走一遍工作流、DeepSeek 最擅長處理的元素,以及那些能產出即轉即用 Markdown 的提示詞。
快速開始:把 DeepSeek 轉成 Word 的 3 步驟
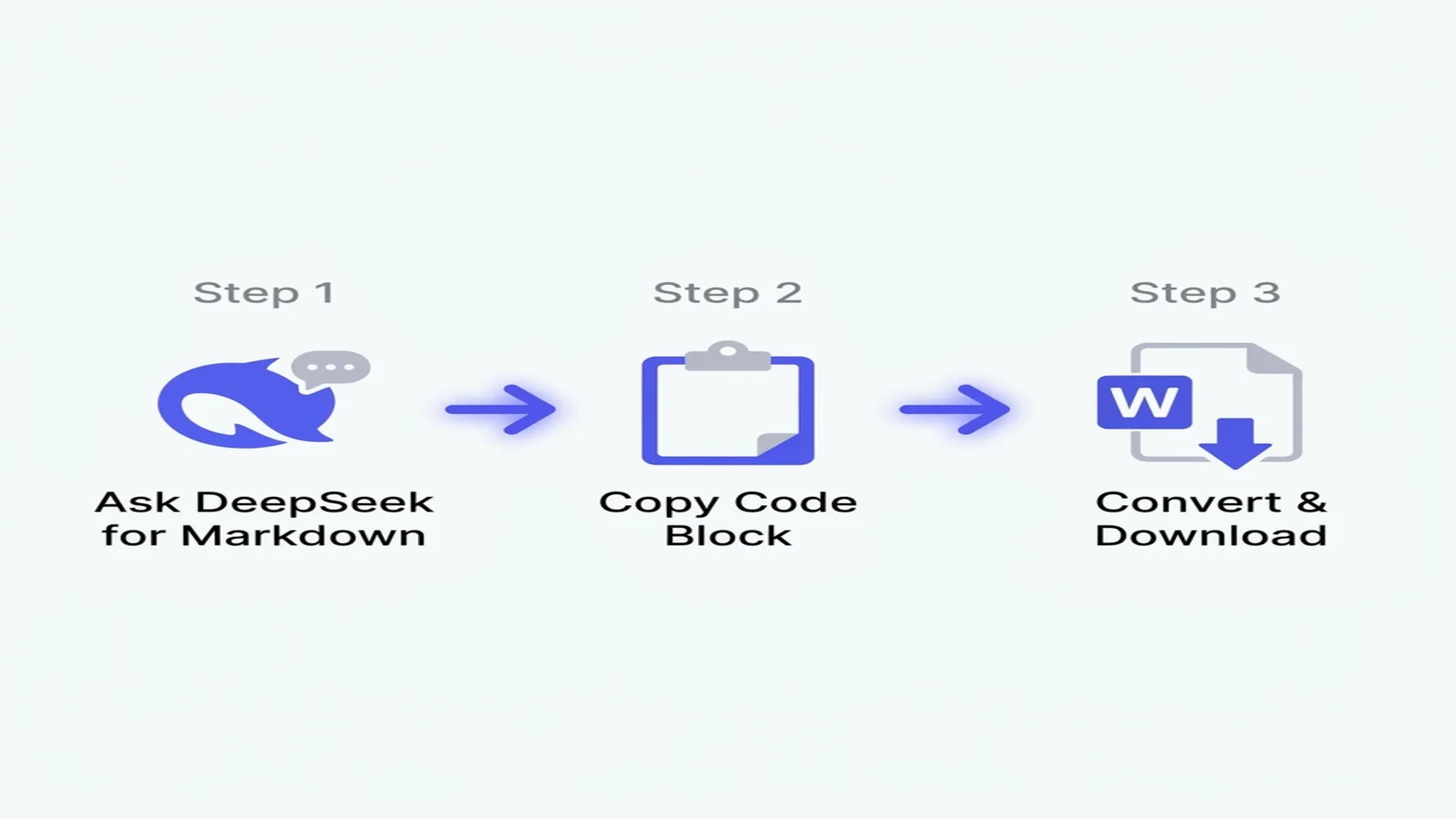
如果你只有 60 秒:
- 在 DeepSeek 提示詞裡加上「以 Markdown 格式」 ——模型會把答案包進一個可複製的程式碼區塊裡。
- 點擊回應右上角的「Copy code」按鈕(不要手動框選文字)。
- 貼到我們的免費轉換器,下載一份乾淨的 DOCX 檔 ——數學、程式碼、中文全部保留。
這就是整個工作流。本指南的其餘部分講的是 DeepSeek 輸出變複雜時該怎麼辦——數學密集的推理鏈、中英混排文件,以及大段程式碼區塊。
👉 跳到分步指南 | 直接看數學與中文專題
為什麼直接複製貼上會破壞 DeepSeek 輸出
DeepSeek 的聊天介面用 HTML 與 CSS 渲染內容——公式用 KaTeX,程式碼用語法標亮套件,中文用系統字型。當你選取文字複製時,瀏覽器交給 Word 的是一團纏在一起的 HTML、行內樣式與字型參照,而 Word 的剪貼簿解析器無法乾淨地解讀它。
有三種失敗模式反覆出現:
- LaTeX 公式被當成原文文字貼出。
$$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$會原樣出現,而不是渲染後的公式。這對大量依賴數學記號的 DeepSeek-R1 輸出尤其痛苦。 - 中文字元回退到一個損壞的字型。 當 Word 中沒有原始字型時,字元會渲染為
□方框或替代字形。這會毀掉你打算分享的任何雙語文件。 - 程式碼區塊失去全部縮排。 Python 的
def區塊塌成一行,語法標亮消失,等寬字型退回成 Calibri。
Markdown 避開了上述每一個問題,因為它是帶語意標記的純文字。Word 轉換器能讀懂這些標記,並把每一個映射到合適的 Word 功能:$$...$$ 變成 Word 公式,圍欄程式碼區塊變成帶格式的程式碼段落,中文字元則以 Unicode 形式插入,不會被字型挾持。
為什麼 Markdown 是 DeepSeek 的正確橋樑
DeepSeek 在海量的 GitHub、arXiv 與技術文件上訓練而成——這些內容全都原生使用 Markdown。該模型預設就會產出乾淨、符合規範的 Markdown,在技術內容上往往比 ChatGPT 或 Gemini 還要乾淨。
對 Word 工作流而言,有三個特性很重要:
- 數學公式是一等公民。 DeepSeek 把 LaTeX 寫在
$$...$$分隔符裡,任何像樣的轉換器都能偵測到並將其轉換成 Word 的 OMML(Office 數學標記語言)。 - 雙語內容保持乾淨。 Markdown 不嵌入字型參照,因此轉換器可以無衝突地套用 Word 的預設亞洲字型(通常是新細明體或微軟正黑體)。
- 程式碼區塊帶語言標籤。
```python與```rust能在轉換中存活下來,下游工具在需要時可重新加上標亮。
如果你一直在手動把 DeepSeek 的內容貼進 Word,這套工作流能消除大部分重複的整理工作。
分步教學:DeepSeek 轉 Word
1:讓 DeepSeek 輸出 Markdown
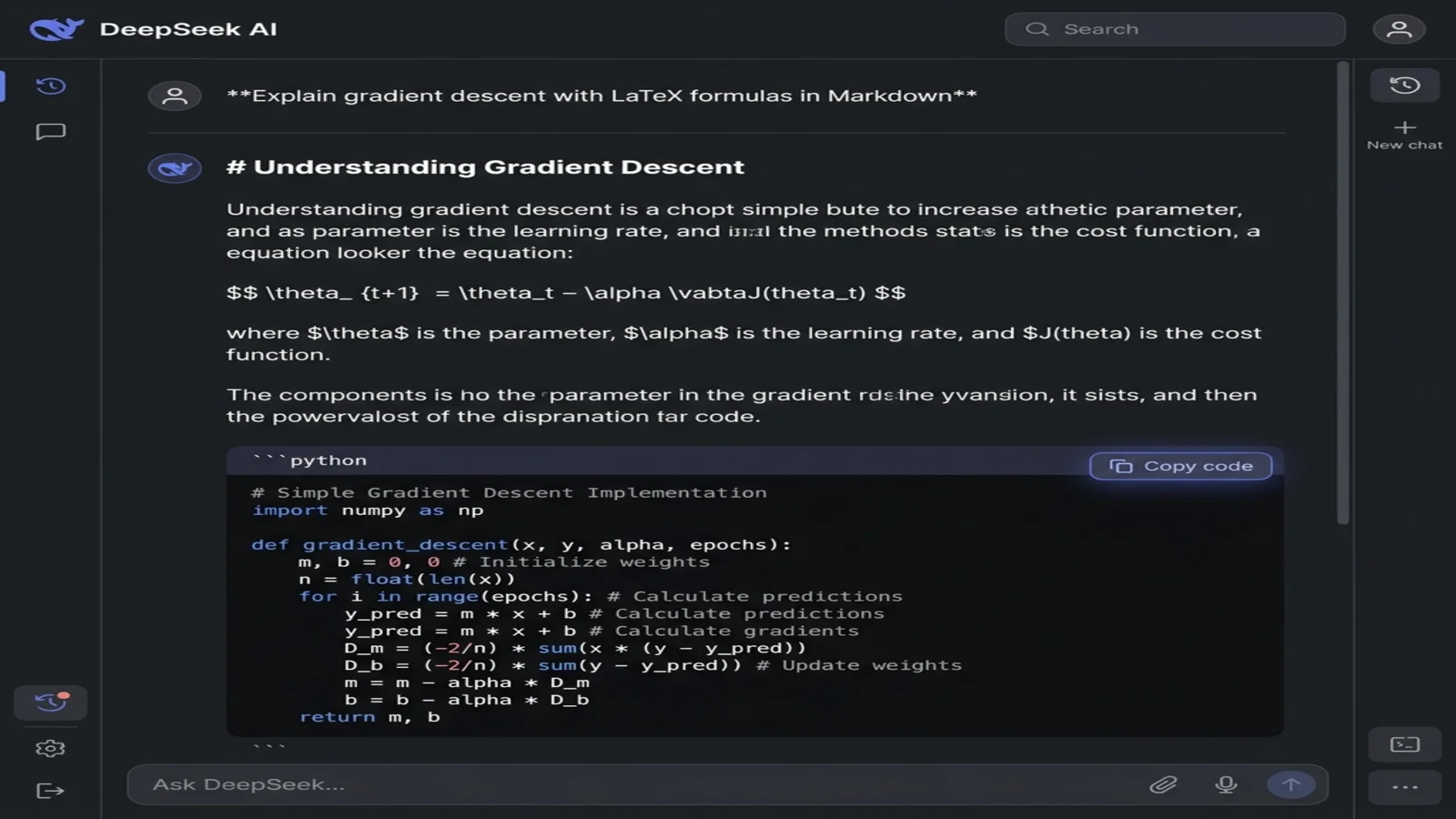
提示詞的措辭決定了 DeepSeek 回傳的是渲染後的 HTML 還是原始 Markdown。多加一句話就能解決:
通用提示詞(回傳渲染後的輸出,難以乾淨複製):
Explain gradient descent with formulas and a Python example
Markdown 感知提示詞(回傳乾淨的程式碼區塊):
Explain gradient descent in Markdown format. Include:
- H2 and H3 headings for sections
- LaTeX equations using $$...$$ delimiters
- A Python code example in a fenced code block
- A summary table at the end
DeepSeek 會用一個包含純 Markdown 的程式碼區塊來回應——標題用 #,公式用 $$ 包裹,程式碼用三重反引號圍欄包裹。你看到的會是語法本身而不是渲染後的版本,而這正是你想要的。
R1(推理模型)專業提示: DeepSeek-R1 會在最終答案之前輸出很長的思維鏈部分。如果你只需要最終成果,加上 Output only the final answer in Markdown, no reasoning trace。
2:複製 Markdown 程式碼區塊
看回應的右上角。DeepSeek 在每個程式碼區塊上都會顯示一個 「Copy code」 按鈕(有時是剪貼簿圖示)。點擊它。
重要:不要手動框選並複製文字。 手動選取會帶上 DeepSeek 的 CSS 樣式,而那正是破壞 Word 的雜訊。複製程式碼按鈕給出的是原始純文字 Markdown——那才是你的轉換器想要的版本。
如果你的 DeepSeek 回應被拆成了多個程式碼區塊,逐個複製並在純文字編輯器裡拼接起來再轉換。
3:轉成 Word
- 開啟 MarkdownToWord.pro。
- 把你的 Markdown 貼到輸入區。
- 點擊「Convert to Word」。
- 下載 DOCX 檔。
轉換只需幾秒鐘,且無需帳號。你的內容僅用於執行此次轉換,並在轉換結束後立即刪除——絕不會被儲存。
處理 DeepSeek 最強的幾類元素
來自 DeepSeek-R1 的 LaTeX 公式

DeepSeek 的推理模型(R1)是目前可用的開源模型中數學能力最強的之一。即使你沒有明確要求,它也經常使用 LaTeX。為確保這些數學內容能順利抵達 Word:
明確要求 LaTeX:
Derive the quadratic formula step by step in Markdown.
Use $$...$$ for display equations and $...$ for inline math.
DeepSeek 會產出類似下面的內容:
The quadratic equation is $ax^2 + bx + c = 0$.
Solving by completing the square gives:
$$x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$$
轉換之後,行內的 $ax^2 + bx + c = 0$ 變成 Word 行內公式,公式區塊變成置中、完全可編輯的 Word 公式。在 Word 裡點擊該公式就會開啟公式編輯器——你可以改變數、加步驟,或把它複製進 PowerPoint。
常見問題: 如果公式轉換後渲染成了純文字,檢查 DeepSeek 用的是不是 $$ 分隔符,而不是 Unicode 數學符號。你可以重新提示 Use LaTeX delimiters $$...$$, not Unicode characters.
中文與雙語文件
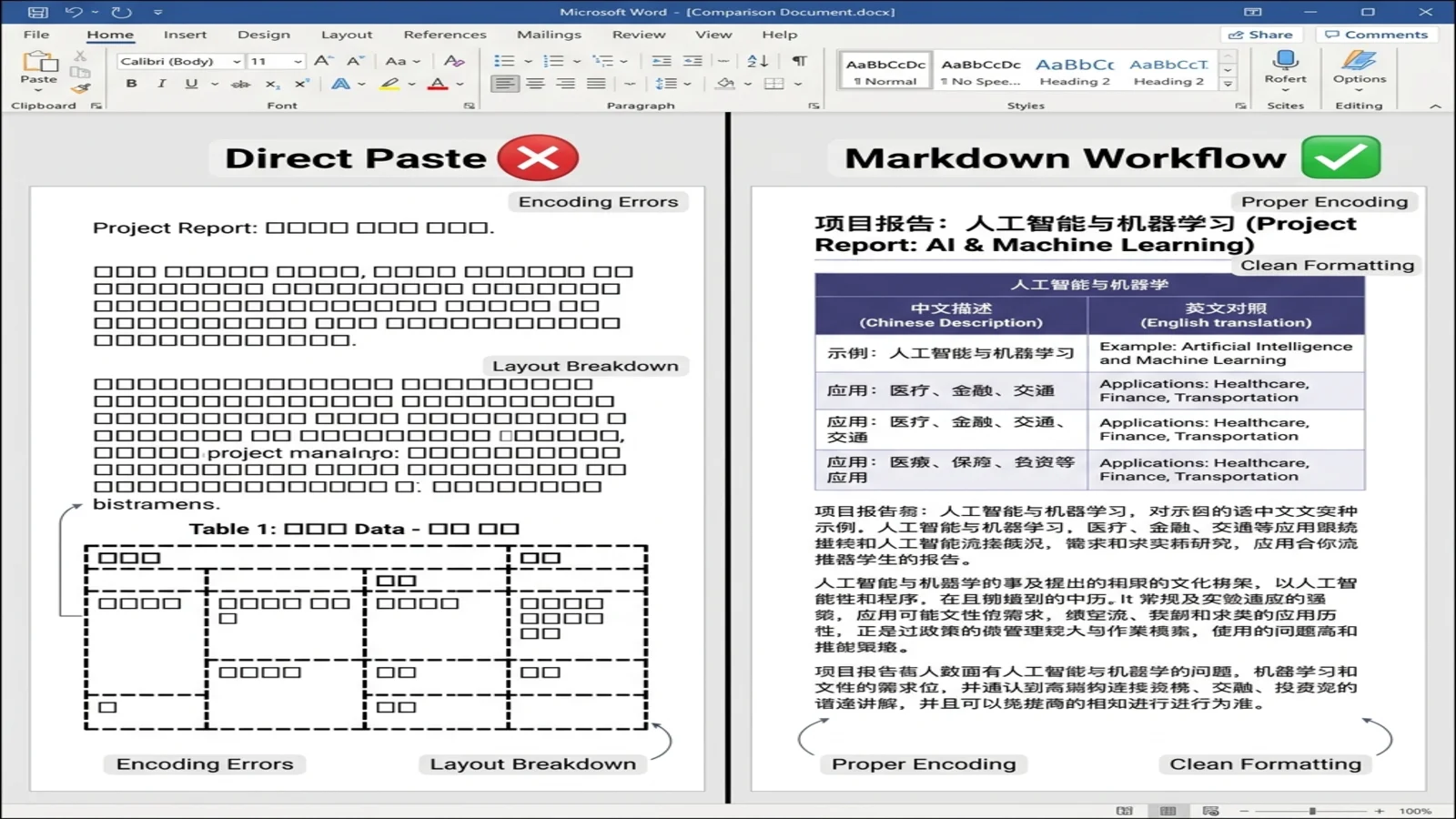
DeepSeek 是少數在中文內容上深度訓練過的前沿模型之一。它的雙語輸出品質對跨境團隊、技術翻譯人員與學術寫作來說都有實打實的價值。Markdown 工作流將這一點完整保留下來。
用於產出乾淨雙語內容的提示詞:
Write a product specification in Markdown with bilingual columns:
- Left column: English
- Right column: Simplified Chinese (简体中文)
Use a Markdown table.
DeepSeek 回傳:
| Feature | English | 中文 |
|---------|---------|------|
| Storage | 5 GB free tier | 5 GB 免费额度 |
| Users | Unlimited | 无限制 |
| Support | Email & chat | 邮件与在线客服 |
轉換後,Word 把它渲染為一個規範的表格,兩種語言都清晰且對齊。Word 會自動回退到它的預設東亞字型(多數系統上是新細明體或微軟正黑體)——無需手動調字型。
繁體中文小提示: 在提示詞裡指定「繁體中文 (Traditional Chinese)」。DeepSeek 兩種字形都能處理得很好,但若不要求則預設用簡體。
程式碼區塊(Python、Rust、JavaScript、SQL)
DeepSeek-Coder 是該模型面向開發者的版本,產出的程式碼輸出在所有 LLM 中算得上最乾淨的之一。要把程式碼轉換成一份真正可讀的 Word 文件:
始終標註你的程式碼語言:
Show me a PyTorch training loop in Markdown.
Use a fenced code block with python language tag.
DeepSeek 回傳:
```python
def train(model, dataloader, optimizer, loss_fn):
model.train()
for batch in dataloader:
optimizer.zero_grad()
loss = loss_fn(model(batch.x), batch.y)
loss.backward()
optimizer.step()
return model
```
轉換到 Word 之後:
- 程式碼段落使用 Consolas(或你系統的等寬字型)
- 4 空格縮排被精確保留
- 背景帶有一抹淡灰底紋,使其從正文中突顯出來
- 程式碼行不會在敘述中途彆扭地換行
如果你正在製作混合正文與程式碼的技術文件,光這一項改動就能讓 Word 重新成為一種可行的輸出格式。
表格與對比矩陣
DeepSeek 的表格輸出符合 GitHub Flavored Markdown(GFM)規範。告訴它欄名,它就會產出一個乾淨的管線符號語法表格:
| Model | Parameters | Context Window | License |
|-------|-----------|----------------|---------|
| DeepSeek-V3 | 671B | 128K | MIT |
| DeepSeek-R1 | 671B | 128K | MIT |
轉換後,你得到的是一個 Word 原生表格,儲存格可編輯、框線乾淨、欄位對齊整齊——不必再手動修正錯位的欄。
準備好試試了嗎?
你已經看過工作流和那些差異化亮點了。這是你的行動計畫:
- 收藏本頁,讓這些提示詞模式一鍵即達。
- 在你下一次 DeepSeek 工作階段裡試試這個 3 步流程 ——如果你想看到最大的「驚艷」效果,就從數學密集的內容開始。
- 分享給團隊裡任何仍在手動把 DeepSeek 複製貼上進 Word 的人。
立即轉換你的 DeepSeek Markdown
免費、快速、無需註冊。
給開發者:DeepSeek 轉 Word 的轉換原理
點擊展開:數學、程式碼與中文的轉換流程
為什麼 DeepSeek 的 Markdown 轉換如此可靠
DeepSeek 的訓練語料嚴重偏向 arXiv 論文、GitHub 倉庫與中文技術論壇——它們全都產出結構化的 Markdown。有三個特性讓它的輸出對下游轉換格外乾淨:
- CommonMark 相容。 DeepSeek 一致地使用
#標題(而非===底線)、圍欄程式碼區塊(而非縮排式)與管線符號表格——全是主流解析器原生處理的 GFM 擴充。 - 穩定的 LaTeX 分隔符。 它預設用
$$...$$表示公式區塊、$...$表示行內公式,這正是每個主流 Markdown 轉 DOCX 套件(pandoc、docx-templates、mdast-util-to-docx)都能識別的分隔符。 - 程式碼區塊上的語言標籤。
```python、```rust、```sql能在轉換中存活,讓渲染器在需要時重新套用語法標亮。
轉換流程
一個轉換器有四項工作:
1. 詞法分析。 把 Markdown 解析成一棵抽象語法樹(AST)——通常用 markdown-it、marked 或 remark。每個標題、段落、公式與程式碼區塊都成為一個節點。
2. AST → DOCX 對應。 走訪 AST,為每個節點輸出 Office Open XML(OOXML):
| Markdown | OOXML 元素 |
|---|---|
# Heading | <w:pStyle w:val="Heading1"/> |
**bold** | <w:b/> |
| 程式碼區塊 | 段落 + <w:shd> 底紋 + 等寬字型 |
$$...$$ | <m:oMath> 區塊 |
3. 公式處理(LaTeX → OMML)。 這是 DeepSeek 輸出受益最大的部分。$$...$$ 裡的 LaTeX 經過解析(通常用 mathjax-node 或 temml),輸出成 Office 數學標記語言:
<m:oMath>
<m:f>
<m:num><m:r><m:t>-b ± √(b² − 4ac)</m:t></m:r></m:num>
<m:den><m:r><m:t>2a</m:t></m:r></m:den>
</m:f>
</m:oMath>
結果是一個能在 Word 公式編輯器中開啟的 Word 公式——完全可編輯,而非一張扁平的圖片。
4. CJK 字型回退。 中文字元需要在 OOXML 中明確指定東亞字型,Word 才能挑對字型:
<w:rPr>
<w:rFonts w:ascii="Calibri" w:eastAsia="SimSun"/>
</w:rPr>
好的轉換器會偵測輸入中的漢字並自動注入這個 run 屬性。
效能說明
轉換速度取決於幾個階段:
- 把 Markdown 解析成 AST 很快,很少成為瓶頸。
- DOCX 組裝 ——建構 OOXML 結構——會隨文件長度增長。
- 公式渲染通常是開銷最大的步驟;一份公式很多的文件明顯比純文字文件耗時更久。
對於典型文件,整個過程仍能在幾秒內完成。一份有數百個公式的文件則會耗時更久。
DeepSeek 提示詞專業技巧
輸出品質在很大程度上取決於你如何構造提示詞。一些行之有效的模式:
用於研究筆記與學習指南:
Summarize [topic] in Markdown with:
- An H2 introduction
- 3-4 H3 subsections
- LaTeX for any equations
- A "Key Takeaways" bullet list at the end
用於技術文件:
Write API documentation in Markdown including:
- H2 per endpoint
- Code examples in ```bash and ```json blocks
- A parameters table with: Name, Type, Required, Description
用於雙語交付物:
Write a project proposal in Markdown, output in two parallel sections:
First in English, then 中文翻译.
Use H2 for each language section.
專門針對 DeepSeek-R1:
Output only the final answer in Markdown.
Do not include the reasoning trace.
需要避開的坑
- 不要要求「帶嵌入式 HTML 的 Markdown」。 Word 轉換器能很好地處理純 Markdown;Markdown/HTML 混合常常會讓解析器混亂。
- 不要省略語言標籤。 不帶標籤的
```仍然能用,但你會失去語法標亮的中繼資料。 - 避免巢狀超過 3 層的清單。 Word 能處理它們,但看起來會很擠。
- 章節之間保留空行。 Markdown 解析器需要靠空行來偵測區塊邊界;沒有空行,標題可能會被併入上一段。
常見問題
問:這套工作流適用於 DeepSeek-R1 的推理輸出嗎?
答:適用。R1 的思維鏈同樣是 Markdown,所以能乾淨地轉換。如果你只想要答案而不要推理過程,在提示詞裡加上 Output only the final answer in Markdown。
問:我能保留 DeepSeek 的粗體與斜體格式嗎?
答:能。Markdown 的 **bold** 與 *italic* 直接對應到 Word 的粗體與斜體樣式。
問:DeepSeek 引用的圖片怎麼辦?
答:目前 DeepSeek 不生成圖片,但如果你用  語法引用圖片 URL,轉換器會自動把圖片插入 Word(當該 URL 可公開存取時)。
問:檔案大小有限制嗎? 答:我們的轉換器最多可處理 10 MB 的 Markdown,足以涵蓋包括書籍篇幅在內的超長文件。再大就把它拆成章節,然後在 Word 裡合併。
問:這適用於繁體中文(繁體中文)嗎? 答:適用。在提示詞裡指定「Traditional Chinese / 繁體中文」,Word 就會用系統預設的繁體中文字型(通常是 PMingLiU 或微軟正黑體)正確渲染。
問:我的 DeepSeek 內容會怎樣? 答:你的 Markdown 透過加密連線傳輸,僅用於執行此次轉換,並在轉換結束後立即刪除——絕不會被永久儲存、讀取或分享。你編輯時的即時預覽是在你的瀏覽器中渲染的。
問:我能取得帶有公司品牌的 Word 文件嗎? 答:轉換後,文件使用標準 Word 樣式(標題 1、標題 2、本文)。透過 Word 的「樣式」窗格套用你公司的範本,就能一鍵為整篇文件加上品牌樣式。
相關資源
繼續完善你的 AI 轉文件工作流:
- ChatGPT 轉 Word:完整匯出指南 — 面向 ChatGPT 使用者的同一套工作流
- 精通 ChatGPT Markdown 輸出提示詞 — 產出即轉即用輸出的提示詞模式
- 面向 AI 與 LLM 的 Markdown — Markdown 為何成為 AI 輸出的通用語
- Markdown 轉換疑難排解 — 表格、程式碼與圖片問題的解決方案
- 如何撰寫 Markdown — 從零開始學 Markdown 語法
或者探索其他格式:
- Markdown 轉 PDF — 以同樣的保真度輸出最終交付的 PDF
- Markdown 轉 HTML — 用於網頁就緒的內容
- 線上 Markdown 編輯器 — 匯出前預覽你的 DeepSeek 輸出
結論
DeepSeek 產出的 Markdown 是所有前沿 LLM 中最乾淨的之一,在數學、程式碼與雙語內容上尤其如此。把這種輸出搬進 Word 的訣竅,是明確要求 Markdown、複製原始程式碼區塊,然後透過一個懂 LaTeX 與 CJK 字元的工具來轉換。
這套三步工作流:
- 讓 DeepSeek 輸出 Markdown
- 點擊「Copy code」
- 用一個能原生處理數學與中文的工具來轉換
公式保持可編輯,中文保持清晰,程式碼保持可讀——每次 DeepSeek 工作階段後都不再需要手動整理格式。
準備好轉換你的第一份 DeepSeek 輸出了嗎?開啟免費轉換器 → 並貼上你的 Markdown。
覺得好用?分享給更多朋友吧!