掌握 ChatGPT Markdown 輸出:必備提示詞與技巧

希望 ChatGPT 每次都回傳排版良好的內容嗎?關鍵在於你如何撰寫提示詞。本指南將展示如何用實用的提示技巧,讓 ChatGPT 生成一致、結構化的 Markdown 回答。
無論你是編寫技術文件的開發者,還是撰寫部落格的內容創作者,懂得如何控制 ChatGPT 的格式化,都能讓它的輸出更易於重複使用。我們將介紹實用的提示詞、格式化技巧,以及如何把這些輸出遷移到專業文件中。
為什麼 ChatGPT 預設生成 Markdown

ChatGPT 傾向於使用 Markdown,原因很簡單:它是一種輕量級標記語言,能添加結構——標題、清單、程式碼區塊——而沒有 HTML 或專有格式的臃腫。這讓一段回答無論作為原始文字還是渲染後的狀態都易於閱讀。
背後的原因
大型語言模型是在海量文字上訓練的,而大量技術內容——GitHub 儲存庫、文件站點、開發者論壇——都是用 Markdown 編寫的。接觸了如此多 Markdown 的模型,自然傾向於生成 Markdown,尤其是在面對技術性或說明性的回答時。
這也帶來了實際的好處:Markdown 沒有相依性。已經是 Markdown 格式的輸出可以直接放進 Pandoc、靜態網站生成器或 Jupyter notebook 等工具,無需額外處理。
結構為何有用
非結構化的純文字容易產生密集的「文字牆」式回答,把有用的部分埋沒其中。Markdown 添加了層級:
- 用標題分隔章節
- 用項目符號呈現清單
- 用圍欄程式碼區塊展示程式碼片段
這種結構讓回答更易於瀏覽、在版本控制中更易於做差異對比,並且通常比臨時排版對螢幕閱讀器更友善。並非所有模型的格式化方式都相同——較小或較舊的模型可能需要明確的格式化指令,而 ChatGPT 往往會自行添加結構。
理解 ChatGPT 的 Markdown 輸出

要充分利用 ChatGPT 的 Markdown,了解它大致能做什麼、不能做什麼會很有幫助。當你要求一個結構化的回答時,模型會根據訓練時學到的模式插入諸如標題的 # 或清單的 - 等語法。它對常見元素很可靠,對邊緣情況則不那麼可靠。
支援的 Markdown 特性
ChatGPT 能處理大部分 GitHub Flavored Markdown(GFM),它在基本 Markdown 之上擴充了表格、任務清單和刪除線。例如,它可以輸出:
## Sample Heading
- Item 1
- Item 2 with **bold** text
| Column 1 | Column 2 |
|----------|----------|
| Data A | Data B |
```python
def hello():
print("World")
```
一個實際的限制:非常長或複雜的表格在冗長的回答中可能會被截斷,因此值得讓生成的表格保持精簡。
回答中的常見元素
ChatGPT 會把你的意圖對應到語法。要求「逐步指南」,它通常回傳有序清單;要求解釋,你得到的是段落。粗體(**text**)和斜體(*text*)用於標記關鍵術語。
它還能處理:
- 用於變數和短程式碼片段的行內程式碼(
`code`) - 用於提示框的引用區塊(
> quote) [anchor](URL)形式的連結
如果你需要嚴格、對解析器友善的 Markdown,明確要求「strict Markdown」可以減少諸如不規則跳脫之類的小問題。
純文字 vs. Markdown
比如說,對某個演算法的純文字解釋可能洋洋灑灑數百字而沒有任何視覺斷點,難以跟讀。同樣的內容用 Markdown 編寫時,會用子標題和清單把資訊分塊,通常能改善可讀性。
這種差異對工具鏈同樣重要:Markdown 一致的分隔符使其比自由形式的散文遠更易於可靠地解析和轉換。主要的注意事項是擴充支援——GFM 表格運作良好,但更小眾的語法(註腳、自訂表情符號)可能並非在所有地方都能渲染。
如何獲得一致的 Markdown 輸出

一致的 Markdown 歸根結底在於清晰的提示詞。把你的格式化指令放在提示詞的靠前位置,讓它塑造整個回答。
從一條簡單的指令開始
像「以 Markdown 格式回答」這樣的基本指令設定了一個基準。例如:
提示詞: "Explain REST APIs in Markdown format."
典型輸出:
# REST APIs Explained
REST (Representational State Transfer) is an architectural style for web services.
## Key Principles
- **Stateless**: Each request contains all the information needed.
- **Client-Server**: Separation of concerns.
加上「use headings and lists」會讓它進一步精確,因此即使是簡短的回答也會以結構化形式回傳,而不是一段平鋪的文字。
針對特定特性進行優化
要瞄準特定元素,就要寫得具體:
範例: "Generate a Markdown table comparing Python frameworks, including links to the docs."
這會回傳一個帶錨點連結的表格,例如 [Django](https://docs.djangoproject.com/)。
對於多部分的輸出,可以鏈式提示:先要求生成內容,再讓模型重新格式化。一些有用的習慣:
- 當你需要表格或任務清單時,指定「GitHub Flavored Markdown」。
- 用「make the lists bulleted」之類的簡短修正進行迭代。
- 讓單次請求的範圍保持合理,這樣長回答就不會在格式中途被截斷。
Markdown 輸出的提示詞範例

下面是從基礎到進階整理的範例提示詞。
基礎提示詞
對於日常任務,這些提示詞能回傳快速、格式化的輸出:
文章寫作
Write a short article on JavaScript closures in Markdown.
回傳標題、加粗的關鍵術語和程式碼區塊。
任務清單
Create a to-do list for deploying a Node.js app in Markdown with checkboxes.
回傳 GFM 任務清單:- [ ] Install dependencies
摘要
Summarize quantum computing basics in Markdown bullets.
回傳易於瀏覽的項目符號清單。
問答
Answer: What is OAuth? Use Markdown headings.
把回答組織在 # Overview、## Flow 等標題之下。
腦力激盪
List 5 blog ideas for AI ethics in Markdown.
回傳一個清晰、層級分明的清單。
進階提示詞
對於技術性輸出,鏈式提示以逐步構建複雜度:
程式碼文件:
First, write a Python sorting algorithm. Then format the explanation
in Markdown with fenced code blocks, a table for Big O complexity,
and a link to the CPython docs.
典型輸出:
## Quicksort Implementation
```python
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
```
### Complexity Analysis
| Operation | Time Complexity | Space Complexity |
|-----------|-----------------|------------------|
| Best | O(n log n) | O(log n) |
| Average | O(n log n) | O(log n) |
| Worst | O(n²) | O(n) |
See [CPython sorting docs](https://docs.python.org/3/howto/sorting.html) for details.
帶數學公式的資料表格:
Generate a Markdown table of ML model benchmarks,
and include LaTeX notation for any equations.
這把 GFM 推得更遠——像 $E = mc^2$ 這樣的行內 LaTeX 在轉換後會渲染為公式。
獲得可靠輸出的最佳實踐
獲得一致的結果與通用的提示工程建議一脈相承:清晰、具體、並不斷迭代。OpenAI 和 Anthropic 都發布了值得一讀的提示工程指南,如果你經常這麼做的話。
在整個工作階段中保持一致
如果你使用 API,系統提示詞可以鎖定格式:
You are a Markdown expert. Always respond in well-structured Markdown.
較低的溫度設定(約 0.2–0.5)能減少波動,而合理的最大 Token 上限可以防止回答在格式中途被切斷。在網頁介面中,重申指令——「format the answer in Markdown」——能防止長對話回退到純文字。
排查不一致的回答
部分格式化,比如缺少程式碼圍欄,通常源於含糊的請求。一些修正方法:
- 當圍欄缺失時,附加「put all code in triple backticks」。
- 對於過長的清單,要求「concise Markdown」。
- 如果回答混用了多種語言,指定「respond in English Markdown」。
將 ChatGPT Markdown 轉換為 Word
ChatGPT 的 Markdown 是很好的草稿,但許多團隊仍然需要 Word 文件來做審閱和簽核確認。轉換彌合了這一差距。
為什麼要轉換為 Word
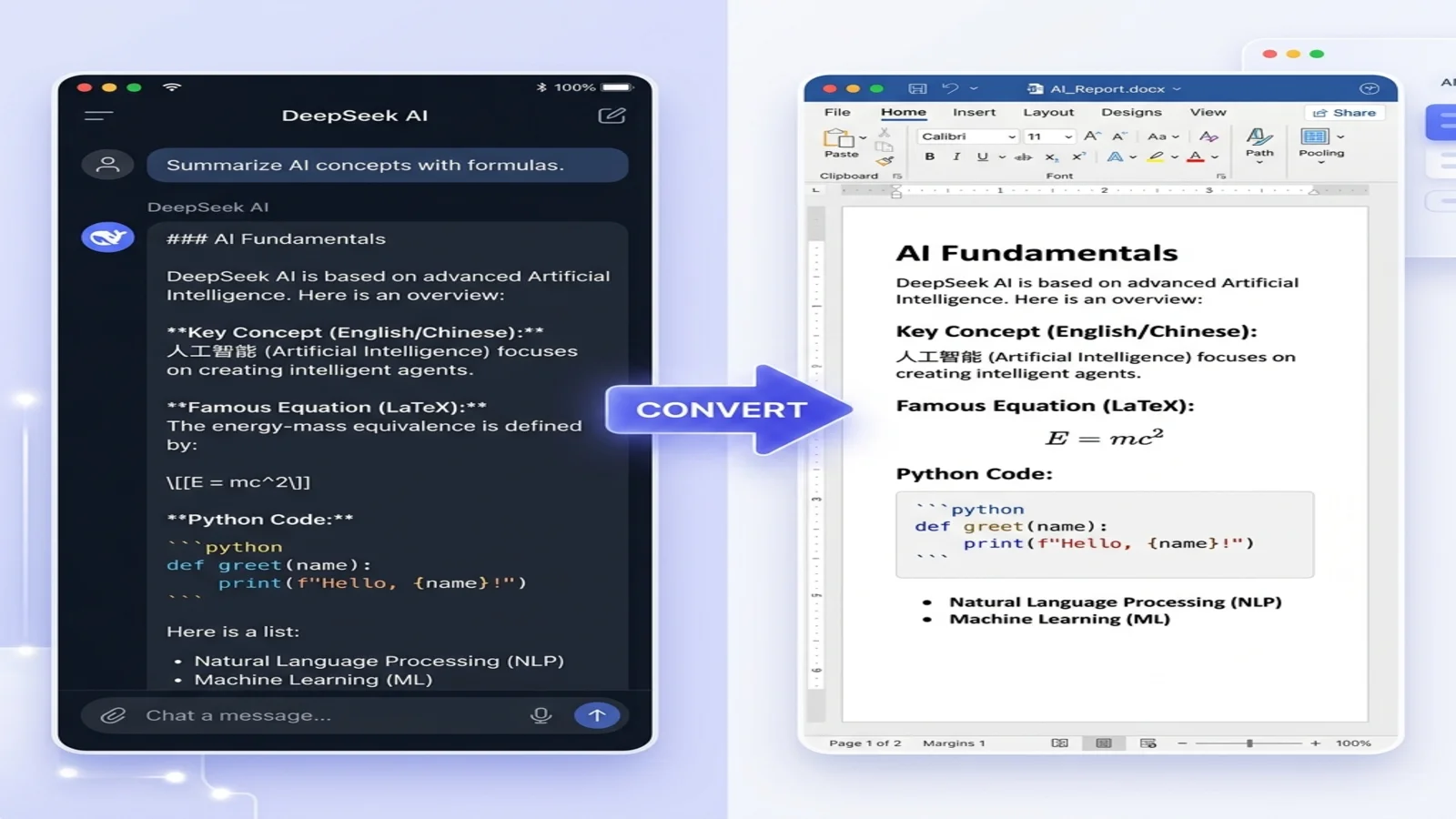
Markdown 適合起草和版本控制;Word 憑藉追蹤修訂和熟悉的樣式適合協作。一個支援 GFM 的轉換器能把標題、表格、程式碼區塊乃至 LaTeX 公式遷移到 .docx 中而無需手動重新排版——之後 Word 還能根據 Markdown 標題自動生成目錄。
關於語法本身的入門,請參閱我們的 Markdown 寫作教學。
逐步轉換
- 從 ChatGPT 複製 Markdown 輸出。
- 開啟 Markdown 轉 Word 轉換器。
- 貼上或上傳你的 Markdown——支援 GFM 表格和程式碼區塊。
- 下載
.docx;粗體、連結和表格都完整保留。 - 在 Word 中開啟做任何最終編輯。
整個過程能處理 LaTeX 數學公式,對於一份普通文件只需幾秒鐘。
真實應用場景
ChatGPT 的 Markdown 輸出能自然地融入內容流程,從初稿到發布皆然。
部落格寫作工作流
一個典型流程:向 ChatGPT 發出提示詞——"draft a post on AI prompting in Markdown"——得到一份結構化草稿,透過 Markdown 轉 Word 工具進行轉換,在 Word 中潤色,然後發布。好處是從一開始就有一致的結構,因此花在重新排版上的時間更少,花在實際內容上的時間更多。把原始 Markdown 直接貼進某些 CMS 編輯器會破壞格式,因此先轉換可以避免這種情況。
技術文件
對於開發者指南,ChatGPT 可以為 README 和 API 文件生成 Markdown 骨架,並附上用於參數和基準測試的表格。在此基礎上,你可以將 Markdown 轉換為 PDF作為最終交付物,或將 Markdown 轉換為 HTML用於網頁發布。由於 Markdown 是模組化的,日後更新某一個章節並不意味著要重新排版整份文件。
常見陷阱及如何避免
ChatGPT 的 Markdown 在結構上很強,但有幾個提示詞錯誤反覆出現。
頻繁的提示詞錯誤
- 過度指定:要求 Markdown 做不到的事情——"use blue links"、"exactly 5 headings at 12pt"——會導致結果不一致。請堅持在語法支援的範圍內。
- 含糊的請求:"List the pros and cons" 可能回傳純文字;"give me a Markdown table of pros and cons with columns X, Y, Z" 則回傳一個規整的表格。
- 程式碼上沒有語言標籤:始終要求附上語言識別碼,這樣程式碼區塊才會被標記(
python 而不是裸的)。
在依賴一個長提示詞之前,先用短提示詞做原型並迭代。
Markdown vs. 其他格式
Markdown 並不是萬能的答案。它適合文字密集、敘述性的輸出,並能乾淨地轉換為其他文件格式。對於結構化的資料交換,JSON 更合適;對於互動式介面,你需要真正的 UI 程式碼。在 Markdown 的優勢——可讀性、可移植性、易於轉換——真正重要的地方選擇它。
常見問題
問:我能在 Claude 或其他 AI 模型上使用這個方法嗎?
答:可以。同樣的 Markdown 提示方式適用於任何能格式化文字的 AI——只需要求「output in Markdown format」。
問:如何保留粗體和斜體格式?
答:Markdown 使用 **bold**、*italic* 和 ***bold italic***,ChatGPT 原生就能生成它們,並且它們會轉換為相應的 Word 格式。
問:數學公式怎麼辦?
答:要求使用 LaTeX 表示法——例如「explain the quadratic formula using LaTeX in Markdown」——ChatGPT 會回傳 $$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$,它會轉換為規整的公式。
問:有長度限制嗎?
答:ChatGPT 的上下文視窗取決於具體模型。對於非常長的文件,分章節處理再合併。
問:對表格管用嗎?
答:管用。要求「a comparison table in Markdown format」並指定欄位;輸出符合 GFM 規範,並能乾淨地轉換。
相關資源
- Markdown 轉 Word 指南:一份完整的轉換教學
- Markdown 轉 PDF:直接轉換為 PDF 作為最終交付物
- Markdown 轉 HTML:建立網頁就緒的內容
- Markdown 寫作教學:從零開始學習語法
結論
控制 ChatGPT 的 Markdown 輸出,主要在於有意識地撰寫提示詞:明確要求 Markdown,指定你需要的元素,並在結果出現偏移時進行迭代。再搭配一個可靠的轉換器,模型的輸出就會成為文件、文章和報告的真正初稿——而不是某種你必須手動重新排版的東西。
準備好把它用起來了嗎?用你的下一條 ChatGPT 回答試試我們免費的 Markdown 轉 Word 轉換器。
覺得好用?分享給更多朋友吧!