DeepSeek을 Word로: 수식·코드·중국어 내보내기 2026
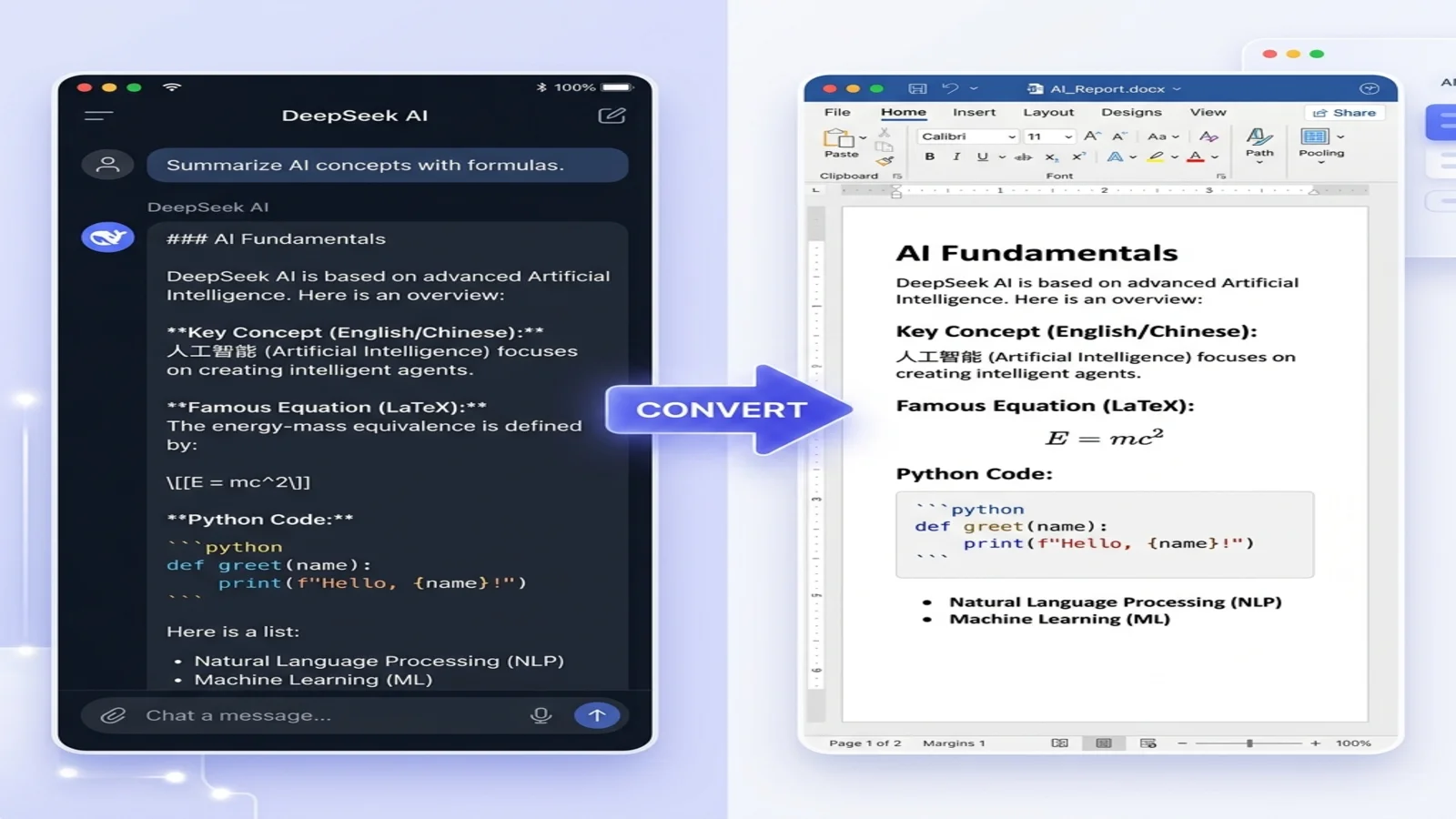
DeepSeek에 수학적 증명과 이중 언어 메모가 포함된 연구 요약을 작성하게 했습니다. 채팅 창에서는 완벽해 보입니다. 그런데 Word에 붙여넣는 순간 모든 게 무너집니다. LaTeX 수식은 $$ 기호 덩어리로 변하고, 중국어 문자는 빈 사각형이 되며, 코드 블록은 들여쓰기의 흔적을 모두 잃습니다. 20분 동안 정리한 끝에 묻게 됩니다. 2026년인데 왜 이게 아직도 이렇게 어렵지?
해결책은 또 다른 서식 플러그인이 아닙니다. 애초에 DeepSeek이 건네주는 형식을 바꾸는 것입니다. DeepSeek에 Markdown을 요청하고, 그 Markdown을 곧바로 Word로 변환하세요 — 수식은 편집 가능한 상태로, 중국어는 선명하게, 코드는 서식이 유지된 채로 남습니다.
Markdown 워크플로우가 이기는 이유
DeepSeek 출력을 Word에 그대로 붙여넣는 것과 Markdown을 거치는 것은 매우 다른 결과를 냅니다 — 특히 DeepSeek이 잘 다루는 수식, 코드, 이중 언어 콘텐츠에서 그렇습니다. 두 방식을 비교하면 다음과 같습니다:
| 항목 | 직접 복사 붙여넣기 | Markdown 워크플로우 |
|---|---|---|
| 정리 작업량 | 붙여넣을 때마다 수동 수정 | 변환 후 다운로드 — 정리 불필요 |
| LaTeX 수식 | $$E=mc^2$$ 원문 텍스트로 붙여넣어짐 | Word 네이티브, 편집 가능한 수식 |
| 중국어 문자 | 자주 빈 사각형 (□□□) | 적절한 폰트 폴백으로 올바르게 렌더링 |
| Python 코드 블록 | 들여쓰기 손실, 고정폭 폰트 없음 | 고정폭 폰트, 들여쓰기 보존 |
| 표 | 테두리 깨짐 | 깔끔한 Word 네이티브 표 |
이 가이드는 워크플로우, DeepSeek이 가장 잘 다루는 요소들, 그리고 변환 가능한 Markdown을 만들어 내는 프롬프트를 다룹니다.
빠른 시작: DeepSeek을 Word로 변환하는 3단계
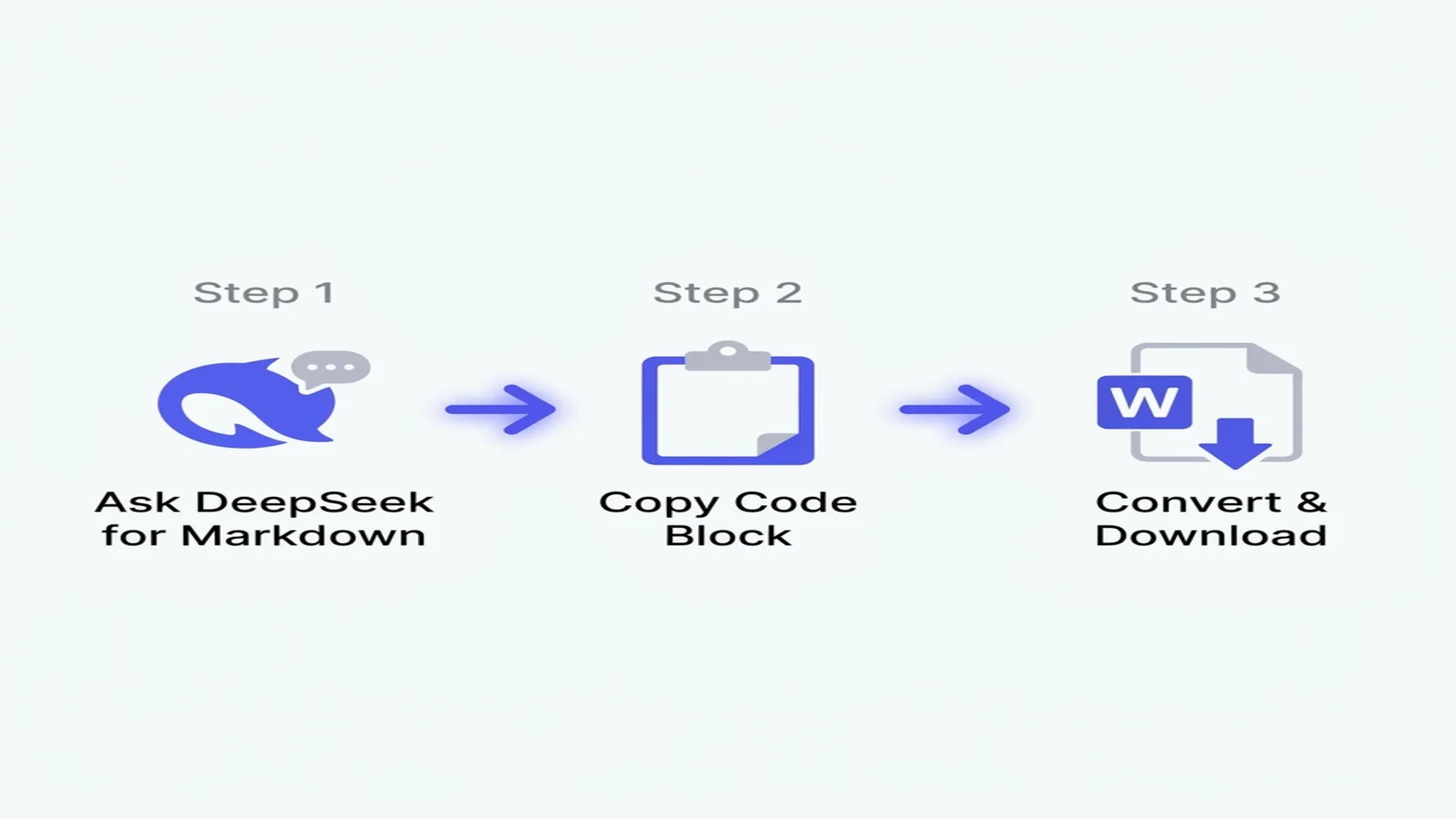
60초밖에 없다면:
- DeepSeek 프롬프트에 "Markdown 형식으로"를 추가하세요 — 모델이 답변을 복사 가능한 코드 블록으로 감싸 줍니다.
- 응답 우상단의 "Copy code" 버튼을 클릭하세요 (텍스트를 직접 선택하지 마세요).
- 무료 변환기에 붙여넣고 깔끔한 DOCX 파일을 다운로드하세요 — 수식, 코드, 중국어 모두 보존됩니다.
이게 워크플로우의 전부입니다. 이 가이드의 나머지는 DeepSeek 출력이 복잡해질 때 — 수식이 많은 추론 체인, 중국어/영어 혼합 문서, 큰 코드 블록 — 무엇을 해야 하는지 다룹니다.
👉 단계별 가이드로 이동 | 수식과 중국어 심화로 이동
직접 복사 붙여넣기가 DeepSeek 출력을 망치는 이유
DeepSeek의 채팅 인터페이스는 HTML과 CSS로 콘텐츠를 렌더링합니다 — 수식은 KaTeX, 코드는 구문 강조 라이브러리, 중국어는 시스템 폰트로 처리합니다. 텍스트를 선택해서 복사하면, 브라우저는 HTML, 인라인 스타일, 폰트 참조가 뒤엉킨 덩어리를 Word에 넘기고, Word의 클립보드 파서는 이를 깨끗하게 해석할 수 없습니다.
세 가지 실패 패턴이 반복적으로 나타납니다:
- LaTeX 수식이 원문 텍스트로 붙여넣어집니다.
$$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$가 렌더링된 수식 대신 글자 그대로 나타납니다. 수학 표기에 크게 의존하는 DeepSeek-R1 출력에서 특히 치명적입니다. - 중국어 문자가 깨진 폰트로 폴백됩니다. 원본 폰트가 Word에 없으면, 문자가
□사각형이나 대체 글리프로 렌더링됩니다. 공유하려던 이중 언어 문서가 통째로 망가집니다. - 코드 블록이 들여쓰기를 모두 잃습니다. Python의
def블록이 한 줄로 뭉개지고, 구문 강조가 사라지고, 고정폭 폰트가 Calibri로 돌아갑니다.
Markdown은 이 모든 걸 우회합니다. 시맨틱 마커가 붙은 평문이기 때문입니다. Word 변환기는 이 마커를 읽어 각각을 적절한 Word 기능에 매핑할 수 있습니다 — $$...$$는 Word 수식이 되고, 펜스드 코드 블록은 서식이 적용된 코드 단락이 되며, 중국어 문자는 폰트 가로채기 없이 유니코드로 삽입됩니다.
DeepSeek에 Markdown이 올바른 다리인 이유
DeepSeek은 방대한 양의 GitHub, arXiv, 기술 문서로 학습되었습니다 — 모두 Markdown을 네이티브로 사용합니다. 이 모델은 기본적으로 깨끗하고 사양에 부합하는 Markdown을 생성하며, 기술 콘텐츠에서는 ChatGPT나 Gemini보다 더 깨끗한 경우가 많습니다.
Word 워크플로우에서 중요한 세 가지 특성:
- 수식이 일급 시민입니다. DeepSeek은 LaTeX를
$$...$$구분자 안에 출력하므로, 제대로 된 변환기라면 이를 감지해 Word의 OMML(Office Math Markup Language)로 변환할 수 있습니다. - 이중 언어 콘텐츠가 깨끗하게 유지됩니다. Markdown은 폰트 참조를 포함하지 않으므로, 변환기는 충돌 없이 Word의 기본 동아시아 폰트(보통 SimSun 또는 Microsoft YaHei)를 적용할 수 있습니다.
- 코드 블록이 언어 태그를 가집니다.
```python과```rust는 변환 후에도 살아남아, 다운스트림 도구가 필요하면 강조를 다시 적용할 수 있습니다.
DeepSeek에서 Word로 수동으로 붙여넣어 왔다면, 이 워크플로우는 그 반복적인 정리 작업의 대부분을 없애 줍니다.
단계별: DeepSeek에서 Word로
1: DeepSeek에 Markdown 출력 요청
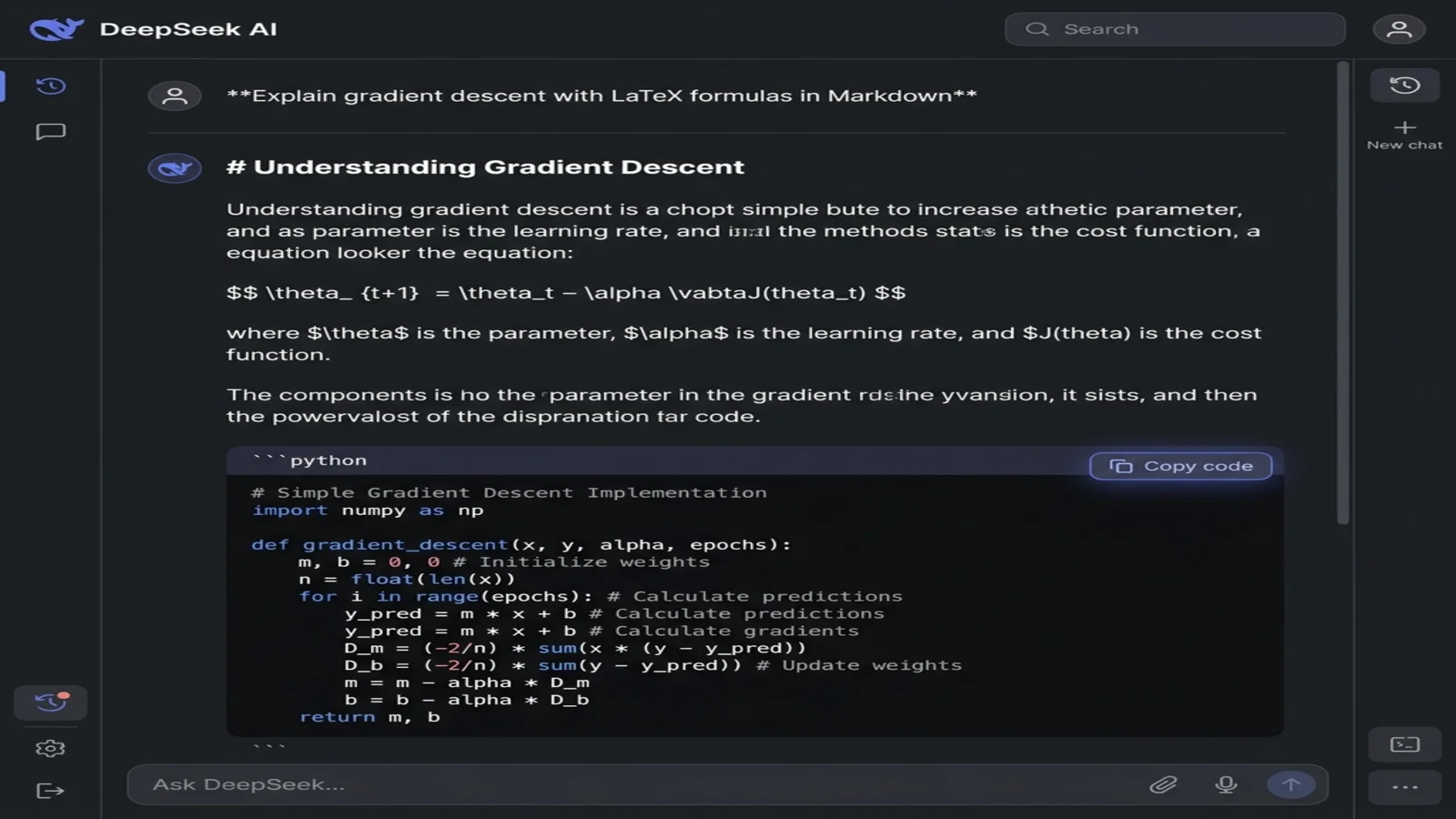
프롬프트의 표현이 DeepSeek이 렌더링된 HTML을 반환할지, 원본 Markdown을 반환할지를 결정합니다. 한 문장만 더 추가하면 해결됩니다:
일반 프롬프트(렌더링된 출력 반환, 깨끗한 복사 어려움):
Explain gradient descent with formulas and a Python example
Markdown 인식 프롬프트(깨끗한 코드 블록 반환):
Explain gradient descent in Markdown format. Include:
- H2 and H3 headings for sections
- LaTeX equations using $$...$$ delimiters
- A Python code example in a fenced code block
- A summary table at the end
DeepSeek은 순수 Markdown이 담긴 단일 코드 블록으로 응답합니다 — 헤딩에는 #, 수식 주위에는 $$, 코드 주위에는 삼중 백틱 펜스. 렌더링된 버전이 아니라 구문 자체가 보일 텐데, 이게 바로 원하는 것입니다.
R1(추론 모델) 프로 팁: DeepSeek-R1은 최종 답변 전에 긴 사고 과정 섹션을 출력합니다. 결과물만 필요하다면 Output only the final answer in Markdown, no reasoning trace를 추가하세요.
2: Markdown 코드 블록 복사
응답의 우상단 모서리를 보세요. DeepSeek은 모든 코드 블록에 "Copy code" 버튼(때로는 클립보드 아이콘으로 표시)을 보여 줍니다. 그것을 클릭하세요.
중요: 텍스트를 수동으로 선택해서 복사하지 마세요. 수동 선택은 DeepSeek의 CSS 스타일까지 가져오는데, 이게 바로 Word를 망가뜨리는 노이즈입니다. 코드 복사 버튼은 순수한 평문 Markdown을 전달하며, 이게 변환기가 원하는 버전입니다.
DeepSeek 응답이 여러 코드 블록으로 나뉘어 있다면, 각각을 복사한 뒤 변환 전에 평문 편집기에서 합치세요.
3: Word로 변환
- MarkdownToWord.pro를 엽니다.
- Markdown을 입력 영역에 붙여넣습니다.
- "Convert to Word"를 클릭합니다.
- DOCX 파일을 다운로드합니다.
변환은 단 몇 초밖에 걸리지 않고 계정도 필요 없습니다. 콘텐츠는 변환을 수행하는 데에만 사용되고 직후에 즉시 삭제됩니다 — 결코 저장되지 않습니다.
DeepSeek의 가장 강력한 요소 다루기
DeepSeek-R1의 LaTeX 수식

DeepSeek의 추론 모델(R1)은 사용 가능한 오픈 모델 중 가장 수학에 능한 모델 중 하나입니다. 명시적으로 요청하지 않아도 LaTeX를 자주 사용합니다. 그 수식이 Word까지 무사히 도달하게 하려면:
LaTeX를 명시적으로 요청:
Derive the quadratic formula step by step in Markdown.
Use $$...$$ for display equations and $...$ for inline math.
DeepSeek은 다음과 같은 것을 출력합니다:
The quadratic equation is $ax^2 + bx + c = 0$.
Solving by completing the square gives:
$$x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$$
변환 후, 인라인 $ax^2 + bx + c = 0$은 Word의 인라인 수식이 되고, 디스플레이 수식은 가운데 정렬된 완전히 편집 가능한 Word 수식이 됩니다. Word에서 수식을 클릭하면 수식 편집기가 열려 — 변수를 바꾸거나, 단계를 추가하거나, PowerPoint로 복사할 수 있습니다.
자주 발생하는 문제: 변환 후 수식이 평문으로 렌더링된다면, DeepSeek이 $$ 구분자를 사용했는지, 유니코드 수학 기호를 사용하지는 않았는지 확인하세요. Use LaTeX delimiters $$...$$, not Unicode characters.로 다시 요청할 수 있습니다.
중국어와 이중 언어 문서
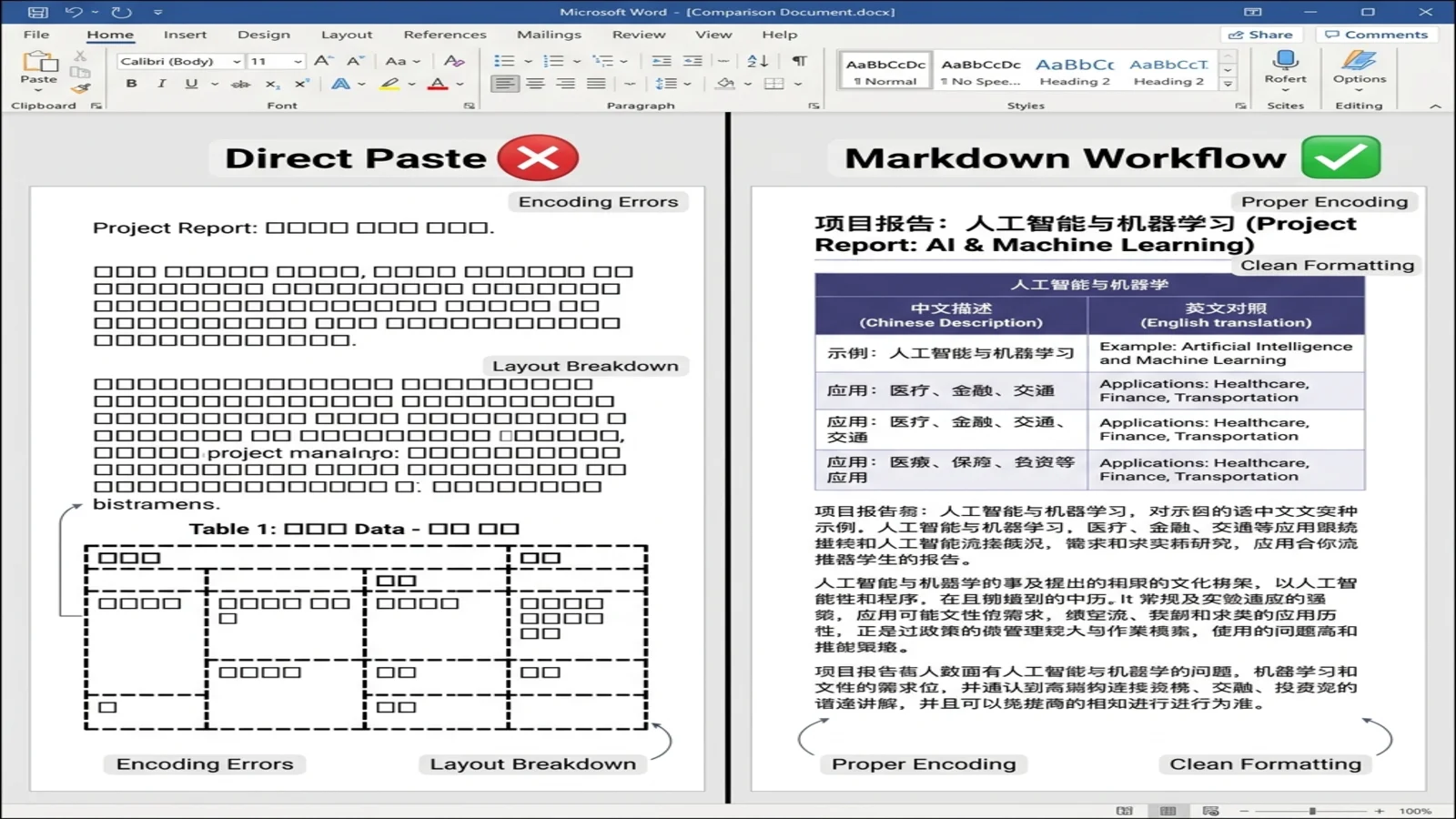
DeepSeek은 중국어 콘텐츠로 깊이 학습된 몇 안 되는 프론티어 모델 중 하나입니다. 그 이중 언어 출력 품질은 글로벌 팀, 기술 번역가, 학술 글쓰기에 진정으로 유용합니다. Markdown 워크플로우는 이를 완전히 보존합니다.
깨끗한 이중 언어 출력 프롬프트:
Write a product specification in Markdown with bilingual columns:
- Left column: English
- Right column: Simplified Chinese (简体中文)
Use a Markdown table.
DeepSeek은 다음을 반환합니다:
| Feature | English | 中文 |
|---------|---------|------|
| Storage | 5 GB free tier | 5 GB 免费额度 |
| Users | Unlimited | 无限制 |
| Support | Email & chat | 邮件与在线客服 |
변환 후 Word는 이를 두 언어 모두 선명하고 정렬된 정식 표로 렌더링합니다. Word는 자동으로 기본 동아시아 폰트(대부분의 시스템에서 SimSun 또는 Microsoft YaHei)로 폴백하므로 — 수동 폰트 수정이 필요 없습니다.
번체 중국어 팁: 프롬프트에 "繁體中文 (Traditional Chinese)"를 지정하세요. DeepSeek은 두 표기 체계 모두 잘 처리하지만, 요청하지 않으면 간체로 기본 설정됩니다.
코드 블록 (Python, Rust, JavaScript, SQL)
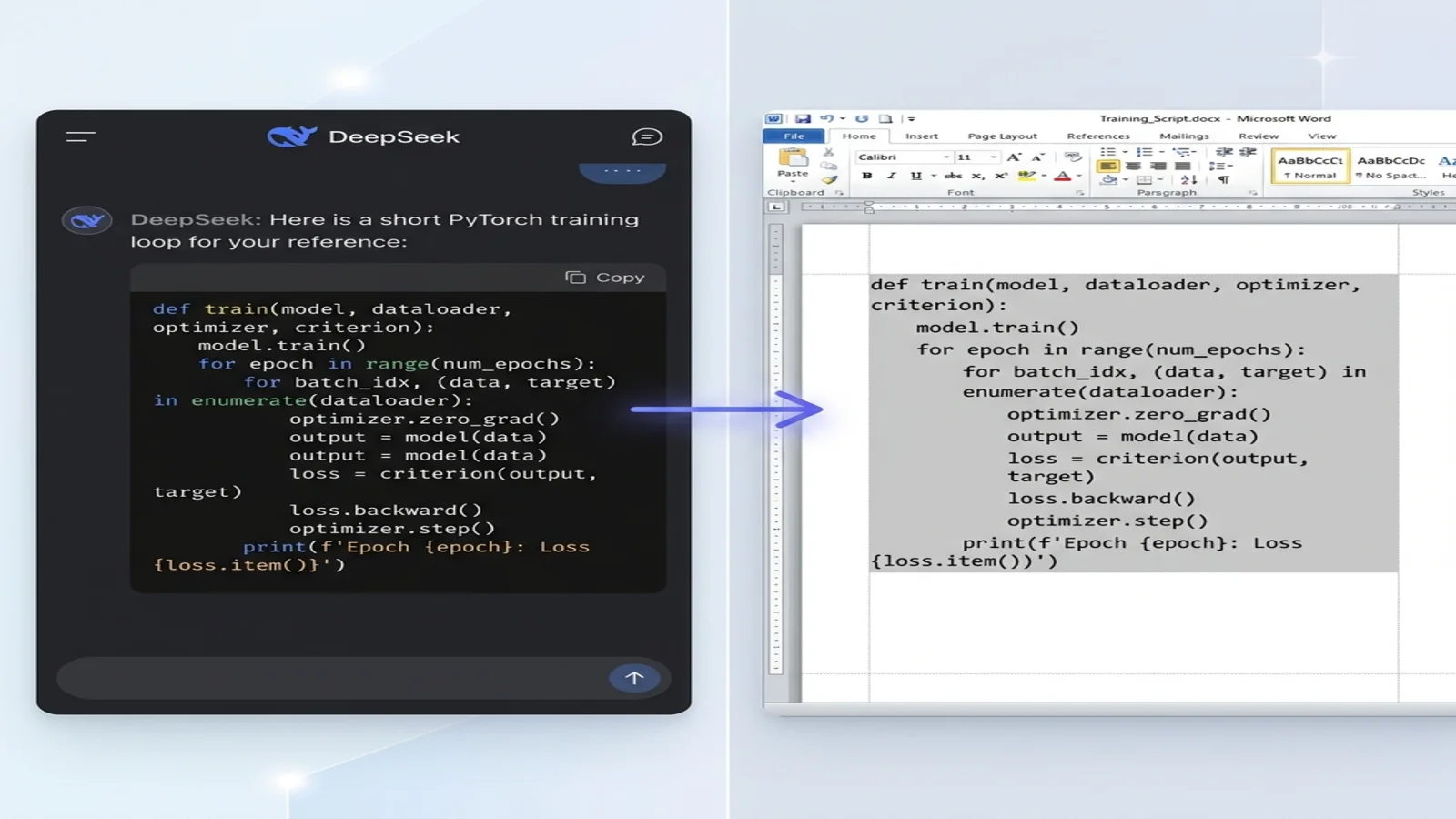
DeepSeek-Coder는 모델의 개발자 중심 변형으로, 어떤 LLM보다도 깨끗한 코드 출력을 생성합니다. 코드를 실제로 읽을 수 있는 Word 문서로 변환하려면:
항상 코드 언어 태그를 붙이세요:
Show me a PyTorch training loop in Markdown.
Use a fenced code block with python language tag.
DeepSeek은 다음을 반환합니다:
```python
def train(model, dataloader, optimizer, loss_fn):
model.train()
for batch in dataloader:
optimizer.zero_grad()
loss = loss_fn(model(batch.x), batch.y)
loss.backward()
optimizer.step()
return model
```
Word로 변환한 후:
- 코드 단락은 Consolas(또는 시스템의 고정폭 폰트)를 사용합니다
- 4스페이스 들여쓰기가 정확히 보존됩니다
- 배경에 옅은 회색 음영이 들어가 본문과 구분됩니다
- 행이 문장 중간에서 어색하게 줄바꿈되지 않습니다
본문과 코드를 섞은 기술 문서를 작성한다면, 이 변경 하나만으로 Word가 다시 실용적인 출력 형식이 됩니다.
표와 비교 행렬
DeepSeek의 표 출력은 GitHub Flavored Markdown(GFM)을 준수합니다. 컬럼을 알려주면 깨끗한 파이프 구문 표를 만듭니다:
| Model | Parameters | Context Window | License |
|-------|-----------|----------------|---------|
| DeepSeek-V3 | 671B | 128K | MIT |
| DeepSeek-R1 | 671B | 128K | MIT |
변환 후에는 편집 가능한 셀, 깔끔한 테두리, 적절한 컬럼 정렬을 갖춘 Word 네이티브 표가 됩니다 — 더 이상 수동으로 잘못 정렬된 컬럼을 고칠 일이 없습니다.
시도해볼 준비가 되셨나요?
워크플로우와 차별화 포인트를 모두 보셨습니다. 행동 계획은 다음과 같습니다:
- 이 페이지를 북마크하여 프롬프트 패턴을 한 번의 클릭으로 참조하세요.
- 다음 DeepSeek 세션에서 3단계 흐름을 시도해보세요 — 가장 큰 "와우"를 보고 싶다면 수식이 많은 것으로 시작하세요.
- 여전히 DeepSeek을 Word에 수동으로 복사 붙여넣기 하는 팀원과 공유하세요.
지금 DeepSeek Markdown을 변환하세요
무료, 빠름, 가입 불필요.
개발자용: DeepSeek-to-Word 변환의 작동 방식
클릭하여 펼치기: 수식, 코드, 중국어 변환 파이프라인
DeepSeek Markdown이 이렇게 안정적으로 변환되는 이유
DeepSeek의 학습 코퍼스는 arXiv 논문, GitHub 저장소, 중국어 기술 포럼으로 크게 기울어져 있습니다 — 모두 구조화된 Markdown을 생성합니다. 세 가지 속성이 그 출력을 다운스트림 변환에 유난히 깨끗하게 만듭니다:
- CommonMark 준수. DeepSeek은 일관되게
#헤딩(===밑줄 아님), 펜스드 코드 블록(들여쓰기 형식 아님), 파이프 표를 사용합니다 — 모두 주류 파서가 네이티브로 처리하는 GFM 확장입니다. - 안정적인 LaTeX 구분자. 디스플레이 수식은
$$...$$, 인라인 수식은$...$를 기본으로 사용하며, 이는 모든 주요 Markdown-to-DOCX 라이브러리(pandoc,docx-templates,mdast-util-to-docx)가 인식하는 구분자입니다. - 코드 블록의 언어 태그.
```python,```rust,```sql는 변환 후에도 살아남아, 렌더러가 필요하면 구문 강조를 다시 적용할 수 있게 합니다.
변환 파이프라인
변환기는 네 가지 일을 합니다:
1. 토큰화. Markdown을 추상 구문 트리(AST)로 파싱합니다 — 보통 markdown-it, marked, remark를 사용합니다. 각 헤딩, 단락, 수식, 코드 블록이 노드가 됩니다.
2. AST → DOCX 매핑. AST를 순회하며 각 노드에 대한 Office Open XML(OOXML)을 출력합니다:
| Markdown | OOXML 요소 |
|---|---|
# Heading | <w:pStyle w:val="Heading1"/> |
**bold** | <w:b/> |
| 코드 블록 | <w:shd> 음영 + 고정폭 폰트가 있는 단락 |
$$...$$ | <m:oMath> 블록 |
3. 수식 처리 (LaTeX → OMML). DeepSeek 출력이 가장 큰 혜택을 보는 부분입니다. $$...$$ 안의 LaTeX가 파싱(보통 mathjax-node 또는 temml)되어 Office Math Markup Language로 출력됩니다:
<m:oMath>
<m:f>
<m:num><m:r><m:t>-b ± √(b² − 4ac)</m:t></m:r></m:num>
<m:den><m:r><m:t>2a</m:t></m:r></m:den>
</m:f>
</m:oMath>
결과는 Word의 수식 편집기에서 열리는 Word 수식입니다 — 평면 이미지가 아니라 완전히 편집 가능합니다.
4. CJK 폰트 폴백. 중국어 문자는 OOXML에서 동아시아 폰트를 명시적으로 지정해야 Word가 올바른 폰트를 선택합니다:
<w:rPr>
<w:rFonts w:ascii="Calibri" w:eastAsia="SimSun"/>
</w:rPr>
좋은 변환기는 입력에서 한자를 감지하여 이 run 속성을 자동으로 주입합니다.
성능 노트
변환 속도는 몇 가지 단계에 따라 달라집니다:
- Markdown을 AST로 파싱하는 것은 빠르며 좀처럼 병목이 되지 않습니다.
- DOCX 조립 — OOXML 구조를 만드는 것 — 은 문서 길이에 따라 늘어납니다.
- 수식 렌더링은 보통 가장 비용이 큰 단계입니다. 수식이 많은 문서는 텍스트만 있는 문서보다 눈에 띄게 오래 걸립니다.
일반적인 문서라면 전체 과정이 여전히 몇 초 안에 완료됩니다. 수백 개의 수식이 있는 문서는 더 오래 걸립니다.
DeepSeek 프롬프트 프로 팁
출력 품질은 프롬프트를 어떻게 구성하느냐에 크게 좌우됩니다. 잘 동작하는 패턴:
연구 노트와 학습 가이드:
Summarize [topic] in Markdown with:
- An H2 introduction
- 3-4 H3 subsections
- LaTeX for any equations
- A "Key Takeaways" bullet list at the end
기술 문서:
Write API documentation in Markdown including:
- H2 per endpoint
- Code examples in ```bash and ```json blocks
- A parameters table with: Name, Type, Required, Description
이중 언어 산출물:
Write a project proposal in Markdown, output in two parallel sections:
First in English, then 中文翻译.
Use H2 for each language section.
DeepSeek-R1 전용:
Output only the final answer in Markdown.
Do not include the reasoning trace.
피해야 할 함정
- "HTML이 포함된 Markdown"을 요청하지 마세요. Word 변환기는 순수 Markdown을 잘 처리하지만, Markdown/HTML이 섞이면 파서가 자주 혼란스러워합니다.
- 언어 태그를 빠뜨리지 마세요. 태그 없는
```도 동작하지만 구문 강조 메타데이터를 잃습니다. - 3단계보다 깊게 중첩된 목록은 피하세요. Word도 처리하지만, 시각적으로 비좁아 보입니다.
- 섹션 사이에 빈 줄을 두세요. Markdown 파서는 블록 경계를 감지하기 위해 빈 줄이 필요합니다. 빈 줄이 없으면 헤딩이 이전 단락에 흡수될 수 있습니다.
자주 묻는 질문
Q: 이 워크플로우가 DeepSeek-R1의 추론 출력에서도 작동하나요?
A: 네. R1의 사고 과정도 Markdown이라 깨끗하게 변환됩니다. 추론 과정이 아닌 답변만 원한다면 프롬프트에 Output only the final answer in Markdown을 추가하세요.
Q: DeepSeek의 굵게/기울임 서식을 보존할 수 있나요?
A: 네. Markdown의 **bold**와 *italic*은 Word의 굵게/기울임 스타일에 직접 매핑됩니다.
Q: DeepSeek이 참조하는 이미지는요?
A: 현재 DeepSeek은 이미지를 생성하지 않지만,  구문으로 이미지 URL을 참조하면 변환기가 자동으로 이미지를 Word에 삽입합니다(URL이 공개적으로 접근 가능한 경우).
Q: 파일 크기 제한이 있나요? A: 변환기는 최대 10 MB의 Markdown을 처리하며, 책 분량의 자료를 포함한 매우 긴 문서까지 커버합니다. 그보다 큰 것은 챕터로 나누어 Word에서 병합하세요.
Q: 번체 중국어(繁體中文)도 작동하나요? A: 네. 프롬프트에 "Traditional Chinese / 繁體中文"을 지정하면, Word가 시스템의 기본 번체 중국어 폰트(보통 PMingLiU 또는 Microsoft JhengHei)로 올바르게 렌더링합니다.
Q: 제 DeepSeek 콘텐츠는 어떻게 되나요? A: 여러분의 Markdown은 암호화된 연결을 통해 전송되고, 변환을 수행하는 데에만 사용되며, 직후에 즉시 삭제됩니다 — 영구적으로 저장되거나, 읽히거나, 공유되지 않습니다. 편집 중의 실시간 미리보기는 브라우저에서 렌더링됩니다.
Q: 회사 브랜딩이 적용된 Word 문서를 받을 수 있나요? A: 변환 후 문서는 표준 Word 스타일(Heading 1, Heading 2, Normal)을 사용합니다. Word의 스타일 창을 통해 회사 템플릿을 적용하면 한 번의 클릭으로 전체 문서를 브랜딩할 수 있습니다.
관련 자료
AI에서 문서로의 워크플로우를 계속 개선하세요:
- ChatGPT를 Word로: 완벽 내보내기 가이드 — ChatGPT 사용자를 위한 동일한 워크플로우
- ChatGPT Markdown 출력 프롬프트 마스터하기 — 변환 가능한 출력을 만드는 프롬프트 패턴
- AI와 LLM을 위한 Markdown — Markdown이 AI 출력의 공용어가 된 이유
- Markdown 변환 문제 해결 — 표, 코드, 이미지 문제 해결책
- Markdown 작성 입문 — Markdown 구문을 처음부터
또는 다른 형식을 탐색하세요:
- Markdown to PDF — 동일한 충실도의 최종 산출물 PDF
- Markdown to HTML — 웹 준비 콘텐츠
- 라이브 Markdown 편집기 — 내보내기 전에 DeepSeek 출력 미리보기
결론
DeepSeek은 어떤 프론티어 LLM보다도 깨끗한 Markdown을 생성하며, 특히 수학, 코드, 이중 언어 콘텐츠에서 두드러집니다. 그 출력을 Word로 가져오는 비결은 명시적으로 Markdown을 요청하고, 원본 코드 블록을 복사하고, LaTeX와 CJK 문자를 이해하는 도구로 변환하는 것입니다.
3단계 워크플로우:
- DeepSeek에 Markdown 요청
- "Copy code" 클릭
- 수식과 중국어를 네이티브로 처리하는 도구로 변환
수식은 편집 가능하게, 중국어는 선명하게, 코드는 읽기 쉽게 — 모든 DeepSeek 세션 후 수동 서식 정리가 필요 없습니다.
첫 번째 DeepSeek 출력을 변환할 준비가 되셨나요? 무료 변환기 열기 → 에서 Markdown을 붙여넣으세요.
이 도구가 유용한가요? 널리 공유해주세요.