DeepSeek в Word: экспорт формул, кода и китайского 2026
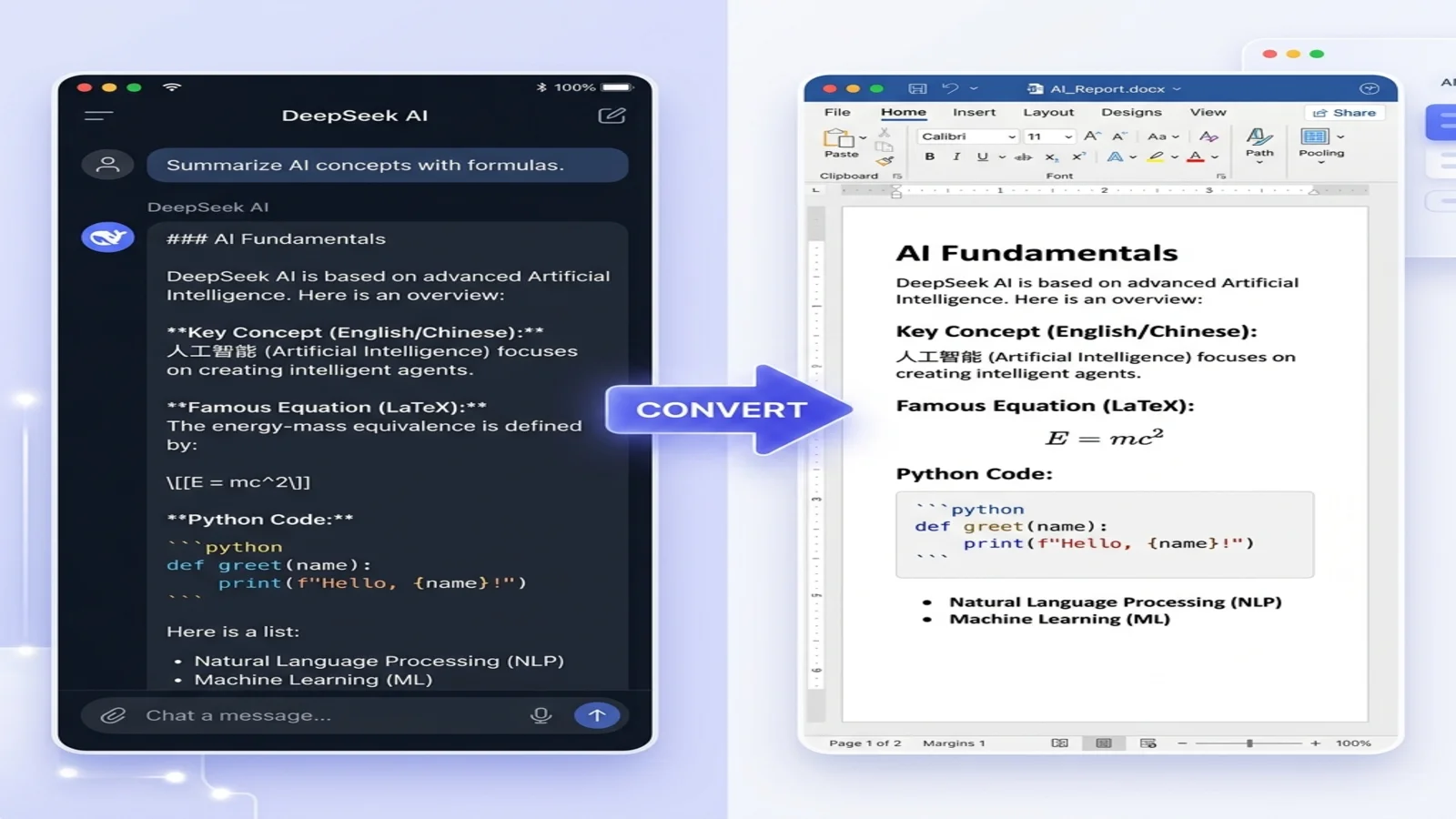
Вы попросили DeepSeek написать сводку исследования с математическими доказательствами и двуязычными примечаниями. В окне чата всё выглядит идеально. Но как только вы вставляете это в Word — всё рушится: LaTeX-формулы превращаются в сырые символы $$, китайские иероглифы становятся пустыми квадратами, а блоки кода теряют все следы отступов. Через 20 минут уборки вы задаётесь вопросом: почему в 2026 году это всё ещё так сложно?
Решение — не очередной плагин форматирования. Решение — изменить формат, который DeepSeek вам отдаёт изначально. Попросите у DeepSeek Markdown и конвертируйте его прямо в Word — формулы остаются редактируемыми, китайский — чётким, код — отформатированным.
Почему Markdown-процесс выигрывает
Вставка вывода DeepSeek напрямую в Word и его прогон через Markdown дают очень разные результаты — особенно для математики, кода и двуязычного контента, с которыми DeepSeek хорошо справляется. Вот как сравниваются два подхода:
| Аспект | Прямое копирование | Markdown-процесс |
|---|---|---|
| Усилия на уборку | Ручные правки после каждой вставки | Конвертируй и скачивай — никакой уборки |
| LaTeX-формулы | Вставляются как сырой текст $$E=mc^2$$ | Нативные редактируемые формулы Word |
| Китайские символы | Часто пустые квадраты (□□□) | Отрисовываются корректно с правильным откатом шрифта |
| Блоки кода Python | Отступы потеряны, шрифт не моноширинный | Моноширинный шрифт, отступы сохранены |
| Таблицы | Сломанные границы | Чистые нативные таблицы Word |
Это руководство объясняет весь процесс, какие элементы DeepSeek обрабатывает лучше всего, и как формулировать промпты, чтобы получать готовый к конвертации Markdown.
Быстрый старт: 3 шага для конвертации DeepSeek в Word
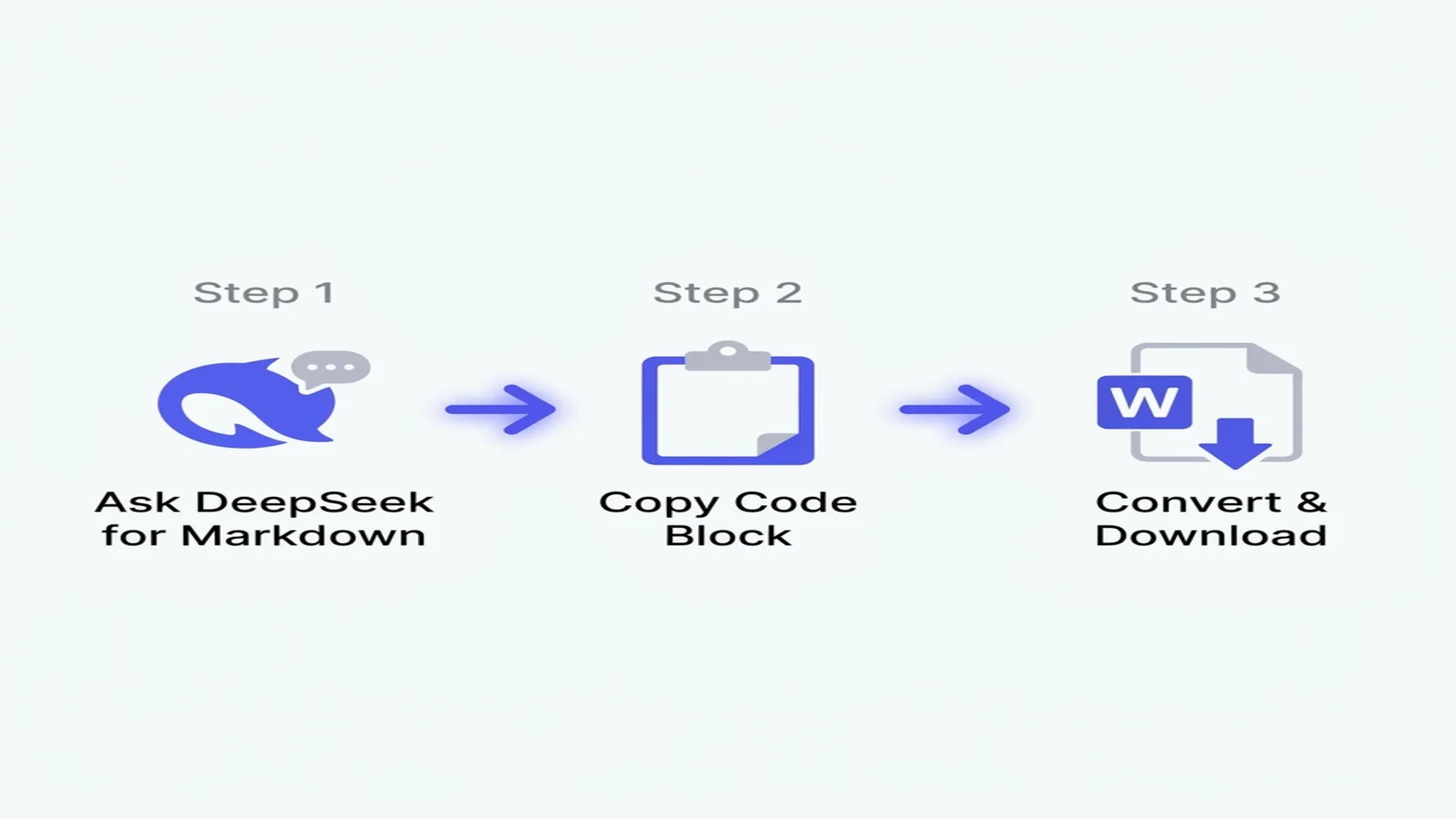
Если у вас всего 60 секунд:
- Добавьте «в формате Markdown» к промпту DeepSeek — модель завернёт ответ в копируемый блок кода.
- Нажмите кнопку «Copy code» в правом верхнем углу ответа (не выделяйте текст вручную).
- Вставьте в наш бесплатный конвертер и скачайте чистый DOCX — математика, код и китайский — всё сохранено.
Это весь процесс. Остальная часть руководства описывает, что делать, когда вывод DeepSeek становится сложнее: длинные математические рассуждения, документы, смешивающие китайский и английский, и большие блоки кода.
👉 Перейти к пошаговому руководству | Перейти к разбору математики и китайского
Почему прямое копирование ломает вывод DeepSeek
Чат-интерфейс DeepSeek рендерит контент через HTML и CSS — KaTeX для формул, библиотеки подсветки синтаксиса для кода, системные шрифты для китайского. Когда вы выделяете текст и копируете, браузер передаёт в Word запутанную смесь HTML, инлайн-стилей и ссылок на шрифты, которую парсер буфера обмена Word не может корректно интерпретировать.
Три типа сбоев повторяются снова и снова:
- LaTeX-формулы вставляются как сырой текст. Например,
$$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$появляется буквально, а не как отрисованная формула. Особенно болезненно с выводом DeepSeek-R1, который активно опирается на математическую нотацию. - Китайские символы откатываются к сломанному шрифту. Когда исходный шрифт недоступен в Word, символы отрисовываются как квадраты
□или замещающие глифы. Любой задуманный двуязычный документ моментально превращается в мусор. - Блоки кода теряют все отступы. Блоки
defв Python схлопываются в одну строку, подсветка синтаксиса исчезает, моноширинный шрифт возвращается к Calibri.
Markdown обходит всё это, потому что это обычный текст с семантическими маркерами. Конвертер в Word читает эти маркеры и сопоставляет каждый с нативной функцией Word: $$...$$ становится формулой Word, огороженные блоки кода — отформатированными абзацами кода, а китайские символы вставляются как Unicode без захвата шрифта.
Почему Markdown — правильный мост для DeepSeek
DeepSeek был обучен на огромных объёмах GitHub, arXiv и технической документации — везде используется Markdown нативно. Модель по умолчанию выдаёт чистый, соответствующий спецификации Markdown, часто более чистый, чем у ChatGPT или Gemini для технического контента.
Три свойства важны для процесса конвертации в Word:
- Математика — гражданин первого класса. DeepSeek выдаёт LaTeX внутри разделителей
$$...$$, которые любой приличный конвертер умеет распознать и преобразовать в Office Math Markup Language (OMML) Word. - Двуязычный контент остаётся чистым. Markdown не встраивает ссылки на шрифты, поэтому конвертер может применить шрифт восточноазиатских языков по умолчанию (обычно SimSun или Microsoft YaHei) без конфликтов.
- Блоки кода несут теги языка.
```pythonи```rustсохраняются после конвертации, поэтому последующие инструменты могут заново применить подсветку, если нужно.
Если вы вставляли вручную из DeepSeek в Word, этот процесс устраняет большую часть той повторяющейся уборки.
Пошагово: DeepSeek в Word
1: Попросите DeepSeek выдать Markdown
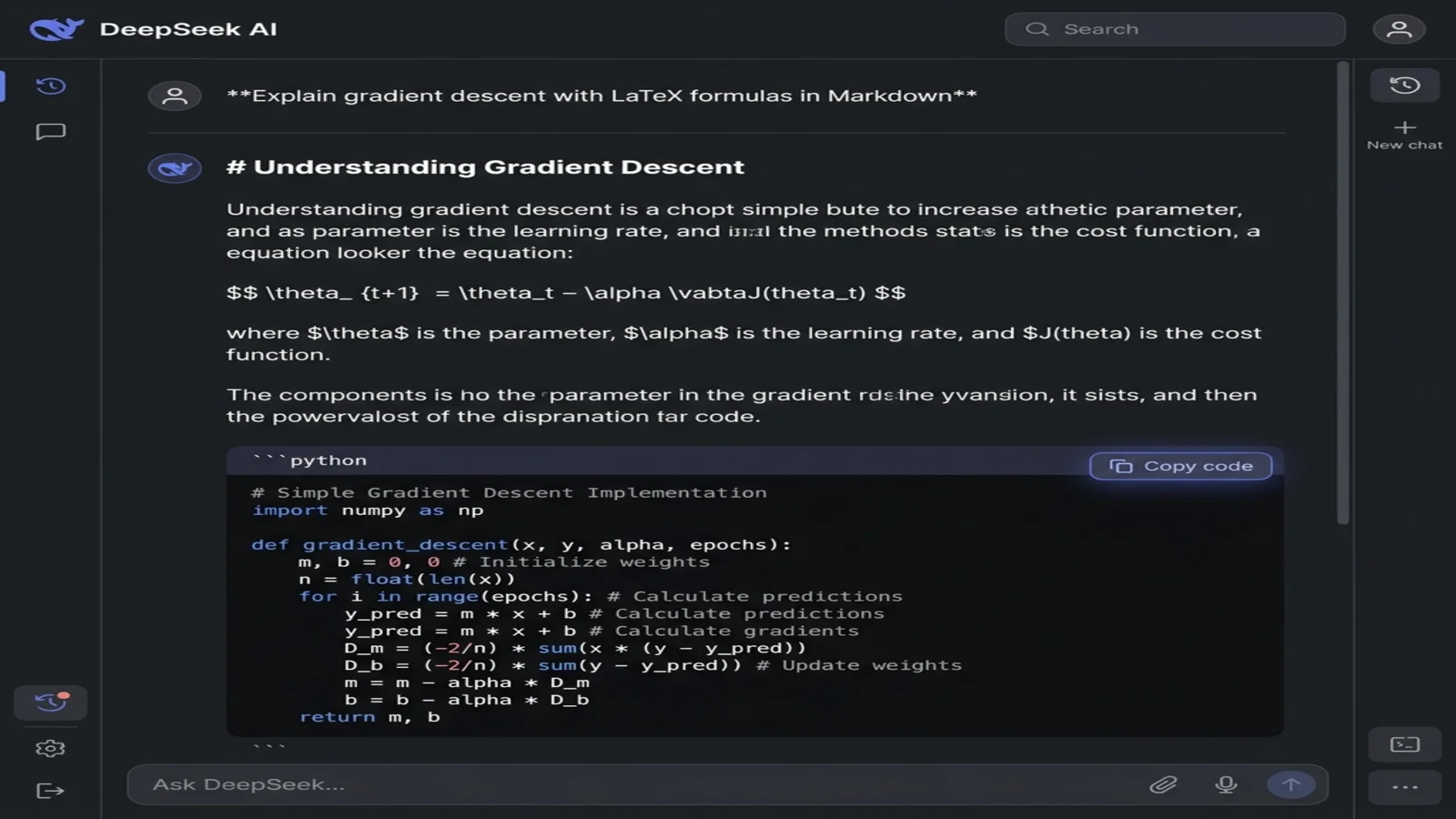
Формулировка вашего промпта определяет, вернёт ли DeepSeek отрисованный HTML или сырой Markdown. Одно дополнительное предложение всё решает:
Общий промпт (возвращает отрисованный вывод, сложно копировать чисто):
Объясни градиентный спуск с формулами и примером на Python
Промпт, учитывающий Markdown (возвращает чистый блок кода):
Объясни градиентный спуск в формате Markdown. Включи:
- Заголовки H2 и H3 для разделов
- LaTeX-формулы с разделителями $$...$$
- Пример на Python в огороженном блоке кода
- Таблицу с резюме в конце
DeepSeek ответит одним блоком кода, содержащим чистый Markdown — # для заголовков, $$ вокруг математики, тройные обратные кавычки вокруг кода. Вы увидите синтаксис вместо отрисованной версии — именно это вам и нужно.
Совет для R1 (модель с рассуждениями): DeepSeek-R1 выдаёт длинные секции цепочек размышлений перед окончательным ответом. Добавьте Output only the final answer in Markdown, no reasoning trace, если вам нужен только результат.
2: Скопируйте блок кода Markdown
Посмотрите на правый верхний угол ответа. DeepSeek показывает кнопку «Copy code» (иногда в виде иконки буфера обмена) на каждом блоке кода. Нажмите её.
Важно: не выделяйте и не копируйте текст вручную. Ручное выделение прихватывает CSS-стили DeepSeek, а это и есть тот шум, который ломает Word. Кнопка копирования кода даёт чистый текстовый Markdown — именно та версия, которую хочет ваш конвертер.
Если ответ DeepSeek разбит на несколько блоков кода, скопируйте каждый и склейте их в текстовом редакторе перед конвертацией.
3: Конвертируйте в Word
- Откройте MarkdownToWord.pro.
- Вставьте Markdown в область ввода.
- Нажмите «Convert to Word».
- Скачайте файл DOCX.
Конвертация занимает всего несколько секунд и не требует аккаунта. Ваш контент используется исключительно для выполнения конвертации и удаляется сразу после неё — он никогда не сохраняется.
Работа с самыми сильными элементами DeepSeek
LaTeX-формулы из DeepSeek-R1

Модель DeepSeek с рассуждениями (R1) — одна из самых математически грамотных открытых моделей. Она часто использует LaTeX, даже когда об этом явно не просят. Чтобы математика пережила путь до Word:
Просите LaTeX явно:
Выведи формулу корней квадратного уравнения шаг за шагом в Markdown.
Используй $$...$$ для блочных формул и $...$ для встроенной математики.
DeepSeek выдаст что-то вроде:
Квадратное уравнение: $ax^2 + bx + c = 0$.
Решение методом выделения полного квадрата:
$$x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$$
После конвертации встроенное $ax^2 + bx + c = 0$ становится встроенной математикой Word, а блочная формула — центрированной полностью редактируемой формулой Word. Кликните по формуле в Word, и откроется редактор формул — можно менять переменные, добавлять шаги или копировать в PowerPoint.
Частая проблема: если ваша формула после конвертации отображается как обычный текст, проверьте, использовал ли DeepSeek разделители $$, а не Unicode-символы математики. Можно перезапросить с Use LaTeX delimiters $$...$$, not Unicode characters.
Китайские и двуязычные документы
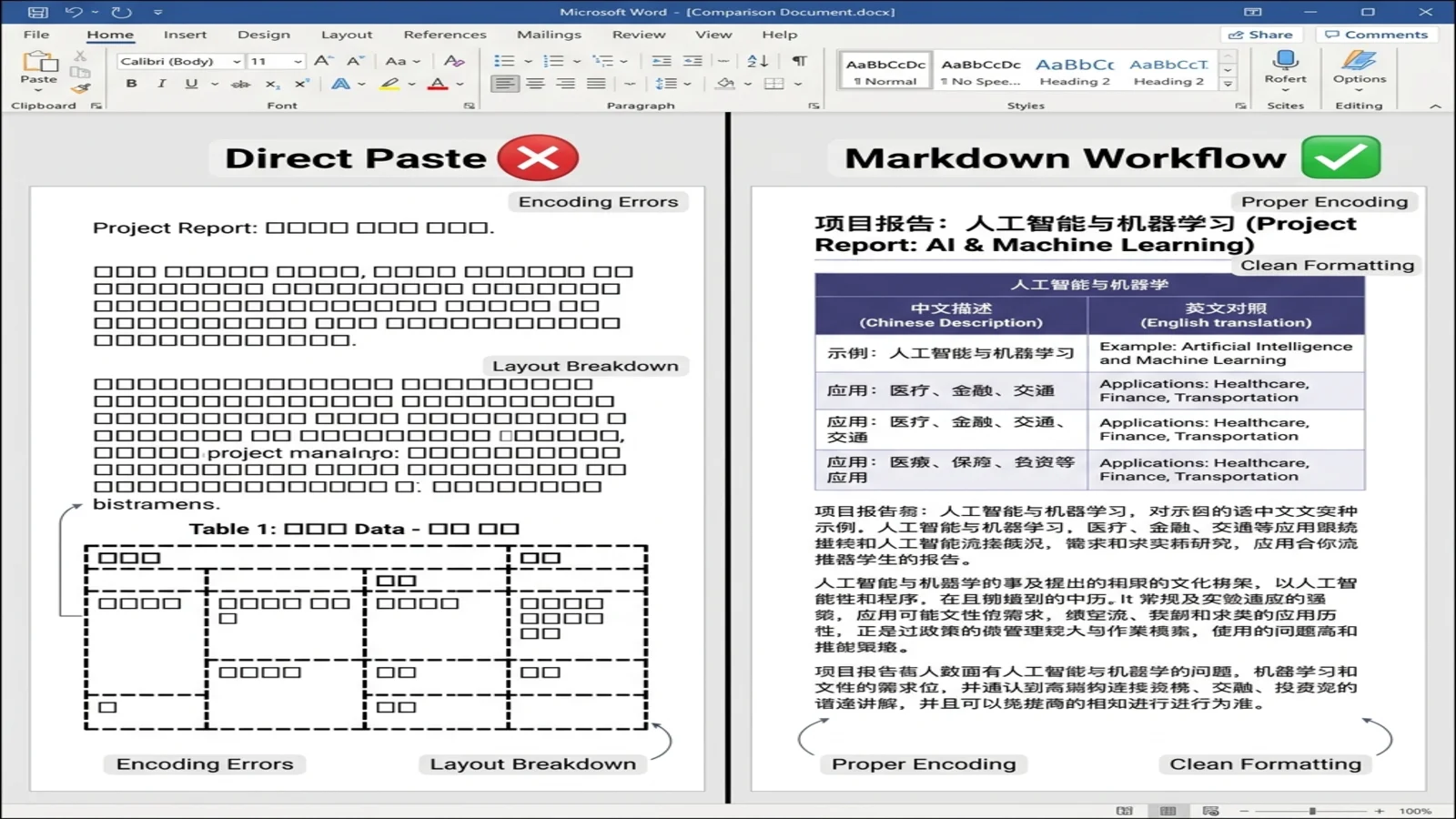
DeepSeek — одна из немногих фронтирных моделей, обученных в большом объёме на китайском контенте. Качество её двуязычного вывода действительно полезно для трансграничных команд, технических переводчиков и академического письма. Markdown-процесс полностью сохраняет это.
Промпт для чистого двуязычного вывода:
Write a product specification in Markdown with bilingual columns:
- Left column: English
- Right column: Simplified Chinese (简体中文)
Use a Markdown table.
DeepSeek возвращает:
| Feature | English | 中文 |
|---------|---------|------|
| Storage | 5 GB free tier | 5 GB 免费额度 |
| Users | Unlimited | 无限制 |
| Support | Email & chat | 邮件与在线客服 |
После конвертации Word отрисовывает это как нормальную таблицу, оба языка чёткие и выровненные. Word автоматически откатывается к восточноазиатскому шрифту по умолчанию (SimSun или Microsoft YaHei на большинстве систем) — никакой ручной правки шрифта не требуется.
Совет по традиционному китайскому: укажите «繁體中文 (Traditional Chinese)» в промпте. DeepSeek хорошо обращается с обеими письменностями, но по умолчанию использует упрощённое.
Блоки кода (Python, Rust, JavaScript, SQL)
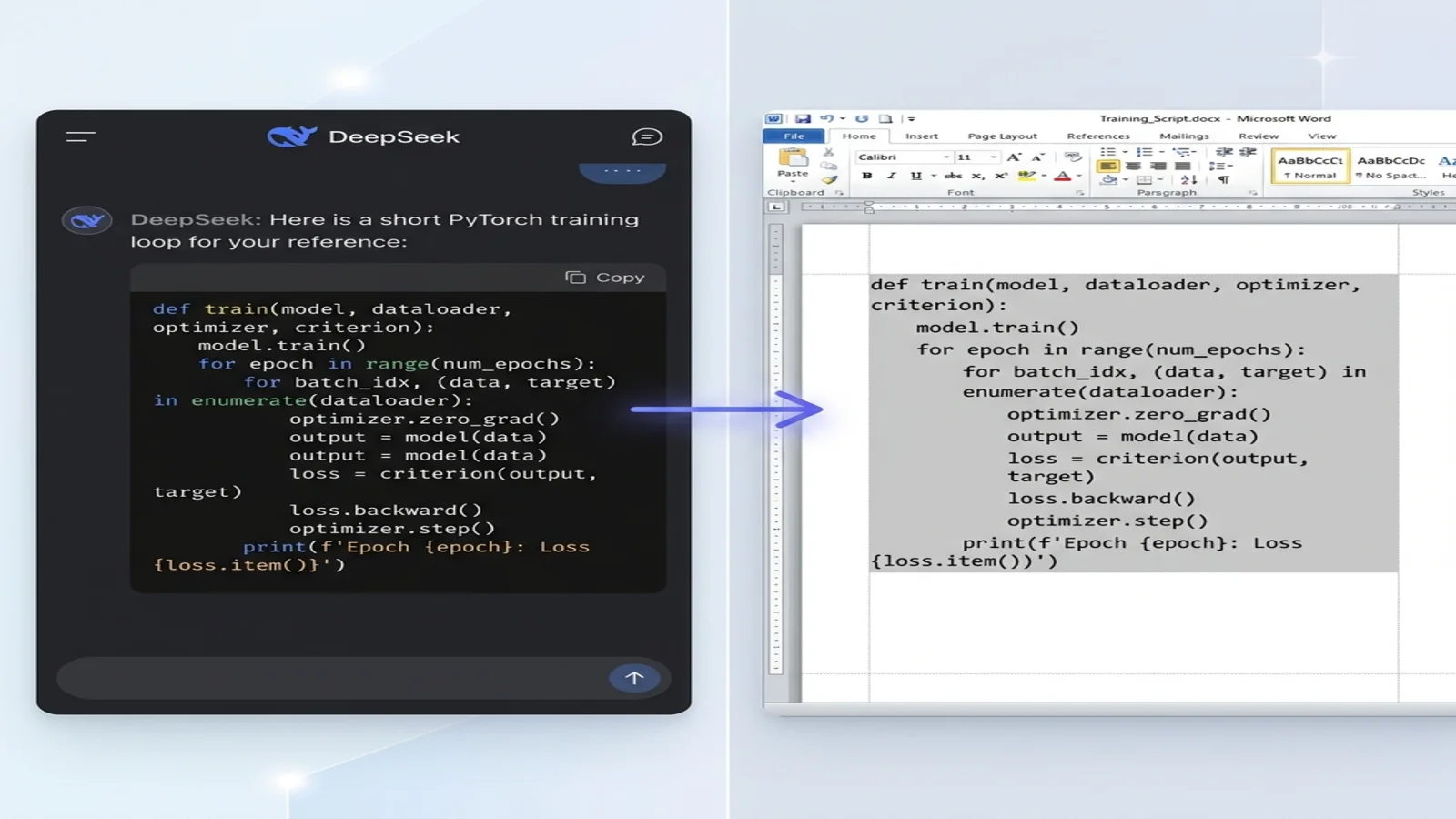
DeepSeek-Coder — это вариант модели, ориентированный на разработчиков, и он выдаёт один из самых чистых результатов кода среди всех LLM. Чтобы конвертировать код в Word-документ, который реально читаем:
Всегда указывайте язык вашего кода:
Show me a PyTorch training loop in Markdown.
Use a fenced code block with python language tag.
DeepSeek возвращает:
```python
def train(model, dataloader, optimizer, loss_fn):
model.train()
for batch in dataloader:
optimizer.zero_grad()
loss = loss_fn(model(batch.x), batch.y)
loss.backward()
optimizer.step()
return model
```
После конвертации в Word:
- Абзац кода использует Consolas (или системный моноширинный шрифт)
- 4-пробельный отступ сохранён точно
- Фон получает лёгкое серое затенение, чтобы выделяться на фоне основного текста
- Строки не разрываются неуклюже посреди инструкции
Если вы создаёте техническую документацию, смешивающую прозу и код, одно это изменение возвращает Word в число рабочих форматов вывода.
Таблицы и матрицы сравнения
Вывод таблиц DeepSeek совместим с GitHub Flavored Markdown (GFM). Скажите ему столбцы — он выдаст чистую таблицу с пайп-синтаксисом:
| Model | Parameters | Context Window | License |
|-------|-----------|----------------|---------|
| DeepSeek-V3 | 671B | 128K | MIT |
| DeepSeek-R1 | 671B | 128K | MIT |
После конвертации вы получаете нативную таблицу Word с редактируемыми ячейками, чистыми границами и правильным выравниванием столбцов — больше не нужно вручную исправлять плохо выровненные столбцы.
Готовы попробовать?
Вы видели процесс и отличительные черты. Вот ваш план действий:
- Добавьте эту страницу в закладки, чтобы шаблоны промптов были в одном клике.
- Попробуйте процесс из 3 шагов в следующей сессии DeepSeek — начните с чего-нибудь математически насыщенного, если хотите увидеть наибольший «вау-эффект».
- Поделитесь с теми коллегами, кто всё ещё копирует и вставляет DeepSeek в Word вручную.
Конвертируйте ваш Markdown DeepSeek сейчас
Бесплатно, быстро и без регистрации.
👉 Попробуйте бесплатный конвертер →
Для разработчиков: как работает конвертация DeepSeek в Word
Нажмите, чтобы развернуть: конвейер конвертации математики, кода и китайского
Почему Markdown DeepSeek так надёжно конвертируется
Тренировочный корпус DeepSeek сильно смещён в сторону статей arXiv, репозиториев GitHub и китайских технических форумов — все они производят структурированный Markdown. Три свойства делают его вывод необычно чистым для последующей конвертации:
- Соответствие CommonMark. DeepSeek последовательно использует заголовки
#(а не подчёркивания===), огороженные блоки кода (а не отступные) и пайп-таблицы — все расширения GFM, которые основные парсеры обрабатывают нативно. - Стабильные разделители LaTeX. По умолчанию использует
$$...$$для блочной математики и$...$для встроенной — те разделители, которые распознаёт каждая основная библиотека Markdown→DOCX (pandoc,docx-templates,mdast-util-to-docx). - Теги языка на блоках кода.
```python,```rust,```sqlсохраняются после конвертации и позволяют рендерерам заново применять подсветку синтаксиса при необходимости.
Конвейер конвертации
У конвертера четыре задачи:
1. Токенизация. Парсинг Markdown в абстрактное синтаксическое дерево (AST) — обычно с помощью markdown-it, marked или remark. Каждый заголовок, абзац, формула и блок кода становится узлом.
2. AST → DOCX-маппинг. Обход AST и выдача Office Open XML (OOXML) для каждого узла:
| Markdown | OOXML-элемент |
|---|---|
# Heading | <w:pStyle w:val="Heading1"/> |
**bold** | <w:b/> |
| Блок кода | Абзац с заливкой <w:shd> + моноширинный шрифт |
$$...$$ | Блок <m:oMath> |
3. Обработка формул (LaTeX → OMML). Здесь вывод DeepSeek получает наибольшую выгоду. LaTeX внутри $$...$$ парсится (обычно mathjax-node или temml) и выдаётся как Office Math Markup Language:
<m:oMath>
<m:f>
<m:num><m:r><m:t>-b ± √(b² − 4ac)</m:t></m:r></m:num>
<m:den><m:r><m:t>2a</m:t></m:r></m:den>
</m:f>
</m:oMath>
Результат — формула Word, открывающаяся в редакторе формул Word, полностью редактируемая, не плоское изображение.
4. Откат шрифта CJK. Китайским символам нужно явное указание восточноазиатского шрифта в OOXML, чтобы Word выбрал правильный:
<w:rPr>
<w:rFonts w:ascii="Calibri" w:eastAsia="SimSun"/>
</w:rPr>
Хорошие конвертеры обнаруживают ханьские символы во входе и автоматически вставляют это свойство run.
Заметки о производительности
Скорость конвертации зависит от нескольких этапов:
- Парсинг Markdown в AST быстр и редко является узким местом.
- Сборка DOCX — построение структуры OOXML — растёт с длиной документа.
- Рендеринг формул обычно самый затратный этап; документ с большим числом формул занимает заметно больше времени, чем чисто текстовый.
Для типичных документов весь процесс всё равно завершается за секунды. Документ с сотнями формул займёт больше времени.
Pro-советы для промптов DeepSeek
Качество вывода сильно зависит от того, как вы формулируете промпт. Шаблоны, которые работают хорошо:
Для исследовательских заметок и учебных пособий:
Summarize [topic] in Markdown with:
- An H2 introduction
- 3-4 H3 subsections
- LaTeX for any equations
- A "Key Takeaways" bullet list at the end
Для технической документации:
Write API documentation in Markdown including:
- H2 per endpoint
- Code examples in ```bash and ```json blocks
- A parameters table with: Name, Type, Required, Description
Для двуязычных результатов:
Write a project proposal in Markdown, output in two parallel sections:
First in English, then 中文翻译.
Use H2 for each language section.
Специально для DeepSeek-R1:
Output only the final answer in Markdown.
Do not include the reasoning trace.
Подводные камни, которых стоит избегать
- Не просите «Markdown с встроенным HTML». Конвертеры Word хорошо справляются с чистым Markdown; смешанный Markdown/HTML часто запутывает парсеры.
- Не пропускайте тег языка.
```без тега всё равно работает, но вы теряете метаданные подсветки синтаксиса. - Избегайте вложенных списков глубже 3 уровней. Word с ними справляется, но они выглядят тесно.
- Оставляйте пустые строки между секциями. Парсерам Markdown они нужны для определения границ блоков; без них заголовки могут быть поглощены предыдущим абзацем.
Часто задаваемые вопросы
В: Работает ли этот процесс с выводом рассуждений DeepSeek-R1?
О: Да. Цепочка мыслей R1 тоже в Markdown, поэтому конвертируется чисто. Добавьте Output only the final answer in Markdown к вашему промпту, если хотите только ответ, без следа рассуждений.
В: Можно ли сохранить полужирное и курсивное форматирование DeepSeek?
О: Да. **bold** и *italic* Markdown напрямую отображаются в стили жирного и курсивного шрифта Word.
В: А как насчёт изображений, на которые ссылается DeepSeek?
О: Сейчас DeepSeek не генерирует изображения, но если вы ссылаетесь на URL изображений с синтаксисом , конвертер автоматически вставляет изображение в Word (когда URL общедоступен).
В: Какое ограничение на размер файла? О: Наш конвертер обрабатывает до 10 МБ Markdown, что покрывает очень длинные документы, включая материалы объёмом с книгу. Для чего-то большего разбейте документ на главы и слейте их в Word.
В: Работает ли это для традиционного китайского (繁體中文)? О: Да. Укажите «Traditional Chinese / 繁體中文» в вашем промпте, и Word корректно отрисует с системным традиционным китайским шрифтом по умолчанию (обычно PMingLiU или Microsoft JhengHei).
В: Что происходит с моим контентом DeepSeek? О: Ваш Markdown отправляется по зашифрованному соединению, используется только для выполнения конвертации и удаляется сразу после неё — он никогда не сохраняется, не читается и не передаётся на постоянной основе. Живой предпросмотр во время редактирования отрисовывается в вашем браузере.
В: Можно ли получить документ Word с фирменным стилем моей компании? О: После конвертации документ использует стандартные стили Word (Heading 1, Heading 2, Normal). Примените шаблон вашей компании через панель «Стили» Word, чтобы за один клик оформить весь документ под бренд.
Связанные ресурсы
Продолжайте улучшать ваш ИИ→документ-процесс:
- ChatGPT в Word: полное руководство по экспорту — тот же процесс для пользователей ChatGPT
- Овладение промптами Markdown-вывода ChatGPT — шаблоны промптов, выдающие готовый к конвертации вывод
- Markdown для ИИ и LLM — почему Markdown стал лингва франка вывода ИИ
- Устранение неполадок конвертации Markdown — решения проблем с таблицами, кодом и изображениями
- Как писать в Markdown — синтаксис Markdown с нуля
Или изучите другие форматы:
- Markdown в PDF — для финальных PDF-доставок с той же точностью
- Markdown в HTML — для готового к веб-публикации контента
- Live-редактор Markdown — предварительный просмотр вывода DeepSeek перед экспортом
Заключение
DeepSeek выдаёт один из самых чистых Markdown среди всех фронтирных LLM, особенно для математики, кода и двуязычного контента. Хитрость, чтобы перенести этот вывод в Word, — попросить Markdown явно, скопировать сырой блок кода и конвертировать через инструмент, понимающий LaTeX и CJK-символы.
Процесс из трёх шагов:
- Попросите у DeepSeek Markdown
- Нажмите «Copy code»
- Конвертируйте через инструмент, нативно работающий с математикой и китайским
Формулы остаются редактируемыми, китайский — чётким, код — читаемым — без ручной уборки форматирования после каждой сессии DeepSeek.
Готовы конвертировать ваш первый вывод DeepSeek? Откройте бесплатный конвертер → и вставьте ваш Markdown.
Нашли этот инструмент полезным? Помогите нам рассказать о нем.