Проблемы конвертации Markdown: LaTeX, таблицы и Mermaid

Ты написал чистый Markdown. Нажал «Конвертировать». А на выходе — совсем не то, что ты ожидал: таблицы поехали, блоки кода превратились в plain text, картинки пропали, а формулы LaTeX стали абракадаброй.
Знакомо? Конвертация Markdown в Word и PDF обычно ломается одними и теми же несколькими способами. Это руководство разбирает 15 самых частых проблем — каждую с её настоящей причиной и конкретным решением.
Шпаргалка: проблема и решение
| Проблема | Вероятная причина | Быстрый фикс |
|---|---|---|
| Колонки таблицы поехали | Ошибки в синтаксисе пайпов | Проверить таблицу линтером |
| Блок кода без подсветки | Не указан язык | Добавить тег языка после ``` |
| Картинки не отображаются | Битый путь или недоступный протокол | Использовать абсолютный URL или base64 |
| LaTeX показывается как текст | Конвертер не поддерживает формулы | Переключиться на инструмент с KaTeX/MathJax |
| Диаграммы Mermaid пропали | Нет движка рендеринга Mermaid | Использовать конвертер с поддержкой Mermaid |
| Вложенные списки схлопнулись | Смешаны табы и пробелы | Стандартизировать отступ в 4 пробела |
| Сноски исчезли | Конвертер игнорирует синтаксис сносок | Проверить поддержку сносок GFM |
| Эмодзи — квадратики | Шрифт не содержит глифы эмодзи | Использовать конвертер с маппингом шрифтов эмодзи |
Проблемы с таблицами
Проблема 1: Колонки таблицы разъехались или слиплись в Word
Что видишь: Аккуратно отформатированная Markdown-таблица превращается в месиво в Word — колонки слиплись, контент вылез за границы, или структура таблицы вообще пропала.
Почему так происходит:
Чаще всего причина — невалидный синтаксис таблицы. Таблицы в Markdown на удивление строгие. Один пропущенный символ пайпа или несовпадающая разделительная строка ломает всю таблицу.
Вот что идёт не так:
<!-- BROKEN: Missing leading pipe -->
Header 1 | Header 2
--- | ---
Cell 1 | Cell 2
<!-- BROKEN: Separator row doesn't match column count -->
| Header 1 | Header 2 | Header 3 |
| --- | --- |
| Cell 1 | Cell 2 | Cell 3 |
Как исправить:
Всегда используй консистентный синтаксис с пайпами и одинаковым количеством колонок:
| Header 1 | Header 2 | Header 3 |
|:---------|:--------:|----------:|
| Left | Center | Right |
| Cell 1 | Cell 2 | Cell 3 |
Основные правила:
- Начинай и заканчивай каждую строку пайпом
| - Разделительная строка должна содержать столько же колонок, сколько в заголовке
- Используй двоеточия для выравнивания —
:---влево,:---:по центру,---:вправо - Не используй объединённые ячейки — стандартный Markdown их не поддерживает. Если нужны объединённые ячейки, придётся править документ Word вручную после конвертации
Совет: Перед конвертацией вставь таблицу в Markdown-линтер или инструмент превью. Большинство редакторов (VS Code, Typora, Obsidian) сразу покажут, если таблица сломана.
Проблема 2: Ширина колонок в Word неравномерная
Что видишь: В Markdown-редакторе таблица отображается корректно, но после конвертации в Word одна колонка занимает 80% ширины страницы, а остальные сжаты.
Почему так происходит:
Большинство конвертеров Markdown в Word рассчитывают ширину колонки по длине содержимого. Если в одной ячейке длинное предложение или URL, а в остальных — короткие значения, распределение получается несбалансированным. В отличие от HTML, в Markdown нет синтаксиса для задания ширины колонок.
Как исправить:
- Держи содержимое ячеек кратким. Длинные описания выноси в сноски или отдельные абзацы под таблицей
- Оформляй длинные URL как текст ссылки: Используй
[Текст ссылки](url)вместо вставки голых URL в ячейки - Используй MarkFlow для конвертации — он по умолчанию применяет сбалансированное распределение колонок, выдавая более читаемые таблицы Word, чем большинство конвертеров
Если нужна точная ширина колонок, правь таблицу в Word после конвертации: выдели таблицу → Свойства таблицы → вкладка Столбец → задай нужную ширину.
Проблема 3: Спецсимволы в содержимом ломают рендеринг таблицы
Что видишь: Символы пайпа | внутри ячеек ломают структуру колонок, или HTML-сущности рендерятся как сырой текст.
Почему так происходит:
Пайп | — это разделитель колонок в Markdown-таблицах. Когда содержимое ячейки содержит литеральный пайп, парсер воспринимает его как границу колонки.
Как исправить:
Экранируй пайп обратным слэшем:
| Command | Description |
|:--------|:------------|
| `echo "a \| b"` | Pipes output through filter |
| `status: pass\|fail` | Shows pass or fail status |
Для других спецсимволов в ячейках таблицы:
- Используй
\|для литеральных символов пайпа - Используй HTML-сущности вроде
&для амперсанда, если нужно - Оборачивай содержимое в бэктики инлайн-кода, чтобы предотвратить интерпретацию Markdown
Проблемы с блоками кода
Проблема 4: Блоки кода теряют подсветку синтаксиса после конвертации
Что видишь: Красиво подсвеченный Python или JavaScript превращается в монохромный plain text в документе Word.
Почему так происходит:
Две типичные причины:
- Не указан язык — ты использовал тройные бэктики без указания языка
- Конвертер не поддерживает подсветку — многие базовые конвертеры вырезают подсветку синтаксиса при экспорте в Word/PDF
Вот разница:
<!-- NO highlighting — missing language tag -->
```
function hello() {
console.log("Hello");
}
```
<!-- WITH highlighting — language specified -->
```javascript
function hello() {
console.log("Hello");
}
```
Как исправить:
Всегда указывай язык после открывающих тройных бэктиков. Популярные идентификаторы языков:
| Язык | Идентификатор |
|---|---|
| JavaScript | javascript или js |
| Python | python или py |
| TypeScript | typescript или ts |
| Bash/Shell | bash или shell |
| JSON | json |
| SQL | sql |
| HTML | html |
| CSS | css |
| Go | go |
| Rust | rust |
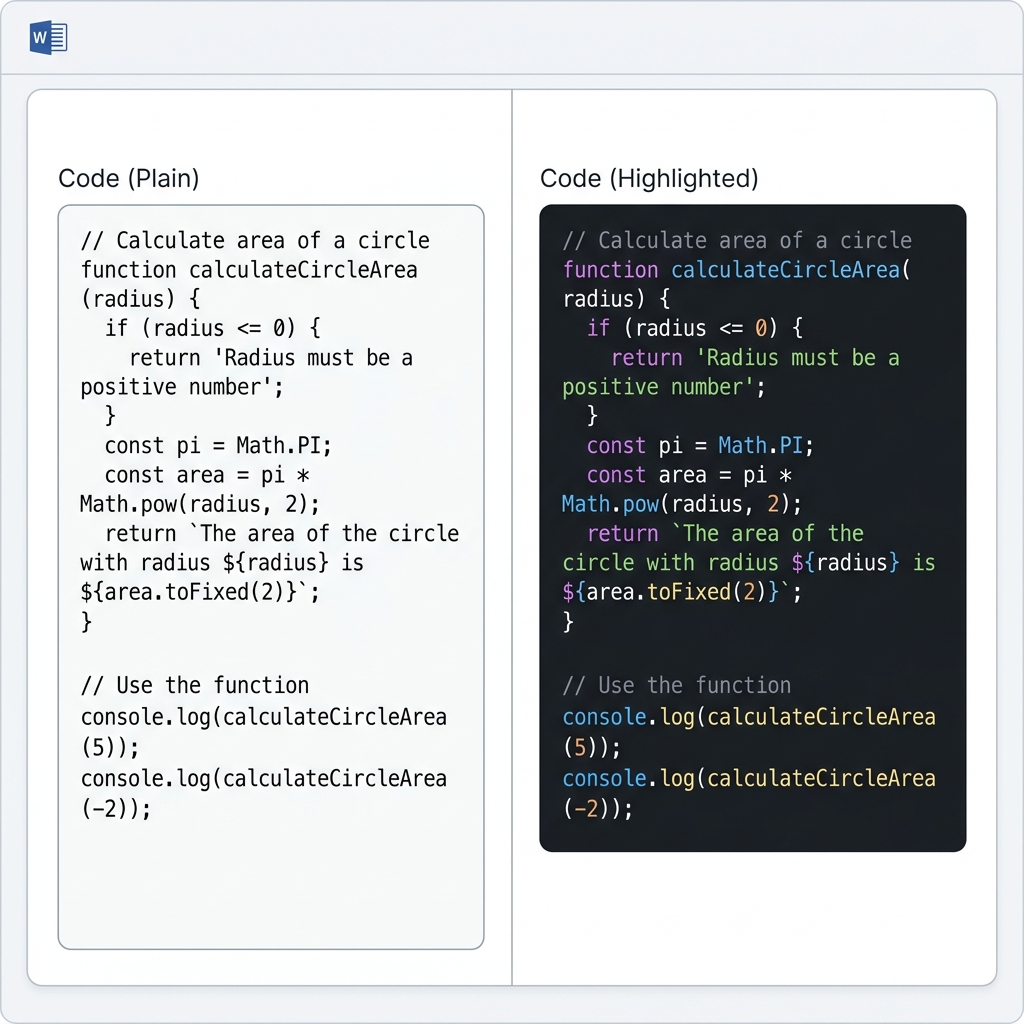
Если конвертер всё равно не даёт подсвеченный вывод, MarkFlow сохраняет подсветку синтаксиса при экспорте и в Word, и в PDF — код получается с правильными цветами, шрифтом и отступами.
Проблема 5: Форматирование инлайн-кода пропадает
Что видишь: Текст в одинарных бэктиках вроде config.yaml или npm install отображается как обычный текст в сконвертированном документе, без визуального отличия.
Почему так происходит:
Некоторые конвертеры обрабатывают инлайн-код как обычный текст и не применяют никаких стилей. Синтаксис бэктиков распознаётся, но выходной формат не включает моноширинный шрифт или фоновый цвет.
Как исправить:
- Используй конвертер, который уважает стили инлайн-кода. MarkFlow рендерит инлайн-код моноширинным шрифтом с лёгким фоном в выводе Word, делая его визуально отличимым от окружающего текста
- Избегай вложенных бэктиков в инлайн-коде. Если код содержит бэктики, используй двойные:
`code with `backtick`→ используй``code with `backtick` `` - Не злоупотребляй инлайн-кодом для выделения — используй жирный или курсив. Бэктики оставь для настоящего кода, команд, имён файлов и технических идентификаторов
Проблема 6: Отступы и пробелы в коде неправильные
Что видишь: Блоки кода в выводе Word с некорректными отступами — либо всё прижато к левому краю, либо табы превратились в неравномерные пробелы.
Почему так происходит:
Конвертация табов в пробелы отличается у разных Markdown-парсеров и движка рендеринга Word. Некоторые конвертеры также вырезают начальные пробелы или схлопывают несколько пробелов в один.
Как исправить:
- Используй пробелы, не табы, в блоках кода Markdown. Большинство стайлгайдов рекомендуют 2 или 4 пробела. Табы интерпретируются по-разному в разных конвертерах
- Используй fenced code blocks (тройные бэктики) вместо indented code blocks (4 пробела). Fenced-блоки парсятся надёжнее:
<!-- PREFERRED: Fenced code block -->
```python
def nested():
if True:
for i in range(10):
print(i)
```
<!-- AVOID: Indented code block (4 spaces) -->
def nested():
if True:
for i in range(10):
print(i)
- Проверяй вывод сразу после конвертации. Если пробелы поехали — проблема в конвертере, а не в твоём Markdown. Попробуй другой инструмент или зарепорти баг
Проблемы с изображениями
Проблема 7: Картинки не отображаются после конвертации
Что видишь: Сконвертированный документ Word или PDF показывает иконки сломанных изображений, пустые места или alt-текст вместо самой картинки.
Почему так происходит:
Это жалоба номер один на конвертацию, и почти всегда дело сводится к путям к изображениям:
- Относительные пути, которые конвертер не может разрезолвить —
работает в редакторе, потому что он знает, где файл. Конвертер может не знать - Удалённые URL, требующие авторизации — картинки в приватных репозиториях GitHub, Google Drive или Notion не скачаются при конвертации
- Проблемы с протоколом — некоторые конвертеры не обрабатывают пути
file://или локальные абсолютные пути - Неподдерживаемый формат файла — отдельные конвертеры с трудом справляются с SVG, WebP или TIFF
Как исправить:
| Сценарий | Решение |
|---|---|
| Использование относительных путей | Конвертировать в абсолютные URL или вставить как base64 |
| Картинки на приватных серверах | Сначала скачать картинку, использовать локальный путь |
| Использование формата SVG | Конвертировать в PNG или WebP перед конвертацией документа |
| Очень большие картинки (>10MB) | Уменьшить размер или сжать перед конвертацией |
Для надёжного подхода используй публично доступные URL картинок:
<!-- Most reliable: absolute URL -->

<!-- Also reliable: base64 embedding (for small images) -->


В MarkFlow: Перетащи .md-файл вместе с папкой картинок — MarkFlow разрезолвит относительные пути автоматически. Можно также вставить Markdown с URL картинок, и они встроятся в вывод Word.
Проблема 8: Картинки слишком большие или слишком маленькие в выводе Word
Что видишь: Изображение, которое идеально смотрится в Markdown-превью, в сконвертированном документе Word выглядит крошечным или огромным, ломая вёрстку страницы.
Почему так происходит:
В Markdown нет нативного синтаксиса для размеров изображений. Формат  не принимает параметры ширины или высоты. Большинство конвертеров вставляют картинки в их оригинальных пиксельных размерах, которые могут не соответствовать ширине страницы Word.
Как исправить:
Некоторые диалекты Markdown поддерживают размеры изображений через HTML:
<!-- Control image size with HTML -->
<img src="./diagram.png" alt="System architecture" width="600" />
Однако не все конвертеры Markdown в Word обрабатывают HTML-теги. Твои варианты:
- Измени размер исходной картинки до примерно 600-800px по ширине перед добавлением в Markdown — это подходит для большинства макетов страниц Word
- Используй HTML-теги img с width, если конвертер поддерживает инлайн-HTML
- Измени размер после конвертации в Word: правый клик по картинке → Размер и положение → задай ширину в нужном проценте
Рекомендуемые размеры изображений для вывода Word:
- Полноширинные картинки: 600–800px по ширине
- Инлайн-диаграммы: 400–500px по ширине
- Иконки или бейджи: 100–200px по ширине
Проблема 9: Base64-картинки не конвертируются
Что видишь: Картинки, встроенные как base64 data URI в Markdown, работают в превью, но в сконвертированном документе показываются как битые или полностью вырезаются.
Почему так происходит:
Картинки в кодировке base64 значительно увеличивают размер файла (примерно на 33% больше бинарного). У некоторых конвертеров есть лимиты размера для инлайн data URI, или они просто не парсят формат data:image/...;base64,....
Как исправить:
- Держи base64-картинки маленькими — до 100KB (примерно 75KB в оригинальном бинарном виде). Иконки и небольшие логотипы работают хорошо; скриншоты и фото обычно нет
- Для всего крупного используй настоящие файлы изображений. Захости их или положи рядом с
.md-файлом - Проверь документацию своего конвертера на предмет поддержки data URI. MarkFlow обрабатывает base64-картинки и в Word, и в PDF, но есть практический лимит около 2MB на картинку
Проблемы с формулами LaTeX и диаграммами Mermaid
Проблема 10: Формулы LaTeX отображаются как plain text
Что видишь: Вместо корректно отрисованного уравнения документ Word показывает сырой исходник LaTeX: $E = mc^2$ или $$\int_{0}^{1} x^2 dx$$ в виде литерального текста.
Почему так происходит:
Поддержка математики LaTeX не является частью стандартного Markdown или GFM. Это расширение, которое требует специальных движков рендеринга (KaTeX или MathJax). Большинство базовых Markdown-конвертеров — включая Pandoc без нужных флагов, VS Code без расширений и Dillinger — не обрабатывают синтаксис LaTeX.
Как исправить:
Сначала проверь, что синтаксис корректный:
<!-- Inline math: single dollar signs -->
The formula $E = mc^2$ describes mass-energy equivalence.
<!-- Block math: double dollar signs -->
$$
\frac{-b \pm \sqrt{b^2 - 4ac}}{2a}
$$
Затем используй конвертер с поддержкой LaTeX:
| Инструмент | Поддержка LaTeX | Примечания |
|---|---|---|
| MarkFlow | Да | Рендеринг KaTeX, инлайн и блок |
| Pandoc | Да | Требует --mathjax или LaTeX-движок |
| Typora | Да | Встроенный KaTeX/MathJax |
| VS Code | Частично | Нужно расширение KaTeX CSS |
| Dillinger | Нет | — |

Типичные ошибки LaTeX, которые ломают рендеринг:
<!-- WRONG: Space after opening $ -->
$ E = mc^2 $
<!-- CORRECT: No space after opening $ -->
$E = mc^2$
<!-- WRONG: Missing closing delimiter -->
$$\int_{0}^{1} x^2 dx
<!-- CORRECT: Matching delimiters -->
$$\int_{0}^{1} x^2 dx$$
Для научных статей и технической документации MarkFlow рендерит LaTeX в настоящие изображения формул в выводе Word — так твои уравнения выглядят правильно даже в версиях Word, которые не поддерживают редакторы формул.
Проблема 11: Диаграммы Mermaid не появляются в выводе
Что видишь: Вместо отрисованной блок-схемы или диаграммы последовательности вывод Word/PDF показывает сырой код Mermaid как обычный блок кода.
Почему так происходит:
Mermaid — это движок рендеринга на JavaScript. Ему нужен браузер или окружение Node.js для генерации визуальной диаграммы. Большинство конвертеров Markdown в Word обрабатывают Markdown чисто как текст и не исполняют JavaScript, поэтому воспринимают Mermaid-блоки как обычный код.
Как исправить:
Сначала проверь синтаксис Mermaid:
```mermaid
graph TD
A[Start] --> B{Decision}
B -->|Yes| C[Action 1]
B -->|No| D[Action 2]
C --> E[End]
D --> E
```
Инструменты, которые рендерят Mermaid в Word/PDF:
- MarkFlow — рендерит диаграммы Mermaid как встроенные изображения в выводе Word. Поддерживает блок-схемы, диаграммы последовательности, диаграммы Ганта и другое
- Typora — рендерит Mermaid в превью и экспортирует в PDF
- Pandoc — требует плагин
mermaid-filter(npm install -g mermaid-filter)
Воркэраунд для конвертеров без поддержки Mermaid:
- Используй Mermaid Live Editor для рендеринга диаграммы
- Экспортируй её в PNG или SVG
- Замени блок кода Mermaid на ссылку на изображение в Markdown
- Конвертируй как обычно
Это добавляет ручной шаг, но гарантирует, что диаграмма появится в выводе любого конвертера.
Проблемы форматирования и структуры
Проблема 12: Уровни заголовков неправильные в выводе Word
Что видишь: Иерархия заголовков в Word не совпадает с твоим Markdown. Заголовки H2 показываются как H1, или все заголовки одного размера.
Почему так происходит:
Две типичные причины:
- Несколько заголовков H1 в твоём Markdown. В документе должен быть только один H1 (заголовок). Некоторые конвертеры объединяют или переназначают заголовки, когда видят несколько H1
- Конвертер маппит Markdown-заголовки на стили Word по-своему. Часть инструментов считает первый заголовок заголовком документа независимо от его уровня
Как исправить:
Соблюдай правильную иерархию заголовков:
# Document Title (H1 — use exactly once)
## Section Title (H2 — main sections)
### Subsection (H3 — within sections)
#### Detail (H4 — rarely needed)
- Никогда не пропускай уровни — не переходи с H2 сразу на H4
- Используй H1 только один раз в начале документа, или пусть конвертер добавит его из метаданных заголовка
- Проверь панель Стилей в Word — заголовки должны отображаться как «Заголовок 1», «Заголовок 2» и т.д. Если они показаны как «Обычный», конвертер замаппил их некорректно
Проблема 13: Вложенные списки теряют отступы
Что видишь: Тщательно вложенный маркированный или нумерованный список в выводе Word выглядит совершенно плоским — все элементы на одном уровне.
Почему так происходит:
Виновата непоследовательная отступация. Markdown требует консистентных отступов для определения уровней вложенности. Смешение табов и пробелов или использование 2 пробелов в одном месте и 3 в другом сбивает парсер с толку.
Как исправить:
Используй 4 пробела (или 1 таб) на каждый уровень вложенности, последовательно:
- First level item
- Second level item
- Third level item
- Back to second level
- Back to first level
1. First item
1. Sub-item one
2. Sub-item two
2. Second item
- Mixed bullet under number
Типичные ошибки:
<!-- BROKEN: Inconsistent indentation (2 spaces then 3) -->
- Item A
- Sub A (2 spaces)
- Sub B (3 spaces — parser gets confused)
<!-- FIXED: Consistent 4-space indentation -->
- Item A
- Sub A
- Sub B
Если конвертер всё равно делает списки плоскими, попробуй сменить конвертер. MarkFlow сохраняет отступы вложенных списков в выводе Word, включая смешанные нумерованные/маркированные списки.
Проблема 14: Сноски пропадают или ломаются
Что видишь: Ссылки на сноски вроде [^1] отображаются как литеральный текст в сконвертированном документе, а содержимое сноски внизу твоего Markdown пропало или отрисовано как обычный абзац.
Почему так происходит:
Сноски — это расширение GFM, а не часть оригинальной спецификации Markdown. Конвертеры, которые поддерживают только базовый Markdown, не обработают синтаксис сносок.
Как исправить:
Правильный синтаксис сносок:
This claim needs a source[^1]. Another point here[^note].
[^1]: Smith, J. (2025). "Research Paper Title." Journal Name.
[^note]: This is a longer footnote with multiple sentences.
Indent continuation lines with 4 spaces.
Убедись, что:
- Ссылка
[^id]и определение[^id]:используют одинаковый идентификатор - Определения сносок расположены в конце документа (или хотя бы после всех ссылок)
- Твой конвертер поддерживает сноски GFM — MarkFlow, Pandoc и Typora справляются с ними корректно
Проблема 15: Символы эмодзи отображаются как пустые квадратики
Что видишь: Эмодзи вроде ✅, 🚀 или ⚠️ отображаются как пустые прямоугольники или знаки вопроса в выводе Word.
Почему так происходит:
Документ Word использует шрифт, в котором нет глифов эмодзи. Когда конвертер маппит текст Markdown в Word, он применяет стандартный шрифт (вроде Calibri или Times New Roman), который может не содержать Unicode-символы эмодзи.
Как исправить:
- После конвертации: Выдели символы эмодзи в Word, смени их шрифт на «Segoe UI Emoji» (Windows) или «Apple Color Emoji» (macOS)
- До конвертации: Если отображение эмодзи критично, рассмотри замену их на текстовые эквиваленты или картинки
- Используй конвертер, который умеет работать со шрифтами эмодзи: MarkFlow маппит символы эмодзи на подходящий системный шрифт в выводе Word, так что они отображаются корректно и в Windows, и в macOS
| Подход | Плюсы | Минусы |
|---|---|---|
| Unicode-эмодзи в Markdown | Просто, стандартно | Рендеринг зависит от шрифта |
HTML-эмодзи (:white_check_mark:) | Выше совместимость | Не все конвертеры парсят шорткоды |
| Замена на картинку | Гарантированное отображение | Лишняя работа, больше файл |
Профилактика: как избежать проблем конвертации до того, как они случатся
Большинство проблем конвертации можно предотвратить. Встрой эти привычки в свой рабочий процесс письма в Markdown:
Валидируй перед конвертацией
Используй Markdown-линтер, чтобы поймать ошибки синтаксиса до того, как они станут проблемами конвертации:
# Install markdownlint CLI
npm install -g markdownlint-cli
# Lint your file
markdownlint document.md
Пользователи VS Code: установите расширение «markdownlint» для проверки в реальном времени.
Используй превью, которое соответствует твоему выводу
Превью твоего редактора и вывод конвертера используют разные движки рендеринга. То, что выглядит нормально в VS Code, может сломаться в Word. Всегда делай тестовую конвертацию перед финальным экспортом.
Стандартизируй свой стиль Markdown
Выбери конвенции и придерживайся их:
- Отступы: 4 пробела для вложенности
- Переводы строк: Одна пустая строка между блоками
- Блоки кода: Всегда fenced (не indented), всегда с тегом языка
- Изображения: Консистентный формат путей (все относительные или все абсолютные)
- Таблицы: Пайпы в начале и конце каждой строки
Держи тестовый документ
Веди Markdown-файл с одним примером каждого элемента, который ты используешь — таблицы, блоки кода, формулы, диаграммы, вложенные списки, сноски, эмодзи. Прогоняй его через конвертер при каждом обновлении инструментов. Это ловит регрессии до того, как они затронут реальные документы.
Какой конвертер для чего использовать
Разные инструменты решают разные наборы проблем:
| Если тебе нужно... | Лучший выбор | Почему |
|---|---|---|
| Чтобы всё работало из коробки | MarkFlow | Обрабатывает GFM, LaTeX, Mermaid, эмодзи и подсветку кода без всякой настройки |
| Научные статьи со сложными формулами | Pandoc с LaTeX-движком | Рендеринг формул высочайшего качества |
| Максимальный контроль над стилями Word | Pandoc с кастомным reference.docx | Подход на основе шаблонов |
| Быстрая конвертация простых документов | Любой браузерный инструмент | Большинство конвертеров нормально справляются с базовым Markdown |
| Пакетная обработка в CI/CD | Pandoc или markdown-pdf | Скриптуемо, автоматизируемо |
Подробное сравнение инструментов конвертации смотри в нашем сравнении конвертеров Markdown в PDF.
Часто задаваемые вопросы
В: Почему моя Markdown-таблица ломается при конвертации в Word? О: Чаще всего причина — непоследовательный синтаксис пайпов: пропущены начальные/концевые пайпы или разделительная строка не совпадает по количеству колонок. Проверь синтаксис таблицы в Markdown-превью перед конвертацией.
В: Как сохранить подсветку синтаксиса в блоках кода при конвертации в Word?
О: Всегда указывай язык после открывающих тройных бэктиков (например, ```python). Затем используй конвертер вроде MarkFlow, который сохраняет подсветку в выводе Word.
В: Почему мои картинки пропадают после конвертации Markdown в Word?
О: Конвертер не может разрезолвить пути к твоим картинкам. Используй абсолютные URL для удалённых картинок или инструмент вроде MarkFlow, который обрабатывает относительные пути, когда ты загружаешь .md-файл с папкой картинок.
В: Можно ли сконвертировать математические формулы LaTeX в Word без потери форматирования? О: Да, но нужен конвертер с поддержкой LaTeX. MarkFlow, Pandoc (с математическими флагами) и Typora рендерят LaTeX корректно. Базовые конвертеры выведут сырой исходник LaTeX как plain text.
В: Почему диаграммы Mermaid показываются как код в моём сконвертированном документе? О: Большинство конвертеров не исполняют JavaScript, который нужен Mermaid. Используй MarkFlow для автоматического рендеринга Mermaid или предварительно отрисуй диаграммы как изображения с помощью Mermaid Live Editor.
В: Как исправить отступы вложенных списков в выводе Word? О: Используй ровно 4 пробела на каждый уровень вложенности в твоём Markdown. Избегай смешения табов и пробелов. Если проблема не уходит — попробуй другой конвертер, некоторые справляются с вложенными списками лучше остальных.
Полезные ресурсы
- Конвертер Markdown в Word — Конвертируй с полной поддержкой форматирования, включая таблицы, код и формулы
- Конвертер Markdown в PDF — Создавай готовые к печати PDF из Markdown
- Конвертер Markdown в HTML — Экспортируй чистый семантический HTML
- Как писать в Markdown — Освой синтаксис, чтобы избежать проблем конвертации
- Руководство по выводу Markdown в ChatGPT — Получай хорошо структурированный Markdown от инструментов ИИ
- Лучшие конвертеры Markdown в PDF — Подробное сравнение инструментов
Нашли этот инструмент полезным? Помогите нам рассказать о нем.