Markdown 转换常见问题排查:LaTeX、表格、Mermaid 一文搞定

你写好了干净的 Markdown,点了「转换」,结果输出和你预期的完全不一样——表格全乱了,代码块变成纯文本,图片消失,LaTeX 公式变成了一串乱码。
是不是很熟悉?Markdown 转 Word 和 PDF 往往就是在那几种相同的方式上翻车。本指南覆盖最常见的 15 个问题——每个都附上真实原因和具体修复方法。
问题速查表:问题 → 修复
| 问题 | 最可能的原因 | 快速修复 |
|---|---|---|
| 表格列错位 | 管道符语法缺失或不一致 | 用 linter 校验表格 |
| 代码块丢失高亮 | 没有指定语言标识符 | 在 ``` 后面加上语言标签 |
| 图片不显示 | 路径无效或协议不支持 | 用绝对 URL 或 base64 嵌入 |
| LaTeX 渲染成纯文本 | 转换器不支持数学公式 | 换用支持 KaTeX/MathJax 的工具 |
| Mermaid 流程图缺失 | 没有 Mermaid 渲染引擎 | 用支持 Mermaid 的转换器 |
| 嵌套列表被拍平 | tab 和空格混用 | 统一用 4 个空格缩进 |
| 脚注消失 | 转换器忽略脚注语法 | 检查是否支持 GFM 脚注 |
| Emoji 显示成方块 | 字体不包含 Emoji 字形 | 用支持 Emoji 字体映射的转换器 |
表格问题
问题 1:表格列在 Word 里错位或合并
你看到的现象: 在 Markdown 里排得整整齐齐的表格,转成 Word 之后变成一团乱——列合并在一起、内容溢出,甚至整个表格结构直接消失。
为什么会这样:
最常见的原因是表格语法无效。Markdown 表格的格式要求其实非常严格。少一个管道符或者分隔行错位,整个表格就会崩。
下面是常见的翻车写法:
<!-- BROKEN: Missing leading pipe -->
Header 1 | Header 2
--- | ---
Cell 1 | Cell 2
<!-- BROKEN: Separator row doesn't match column count -->
| Header 1 | Header 2 | Header 3 |
| --- | --- |
| Cell 1 | Cell 2 | Cell 3 |
怎么修:
始终使用一致的管道符语法,并保持列数匹配:
| Header 1 | Header 2 | Header 3 |
|:---------|:--------:|----------:|
| Left | Center | Right |
| Cell 1 | Cell 2 | Cell 3 |
几个关键规则:
- 每行首尾都要有管道符
| - 分隔行的列数必须和表头一致
- 用对齐冒号 ——
:---左对齐,:---:居中,---:右对齐 - 不要用合并单元格 —— 标准 Markdown 不支持。如果需要合并单元格,转换后必须在 Word 文档里手动编辑
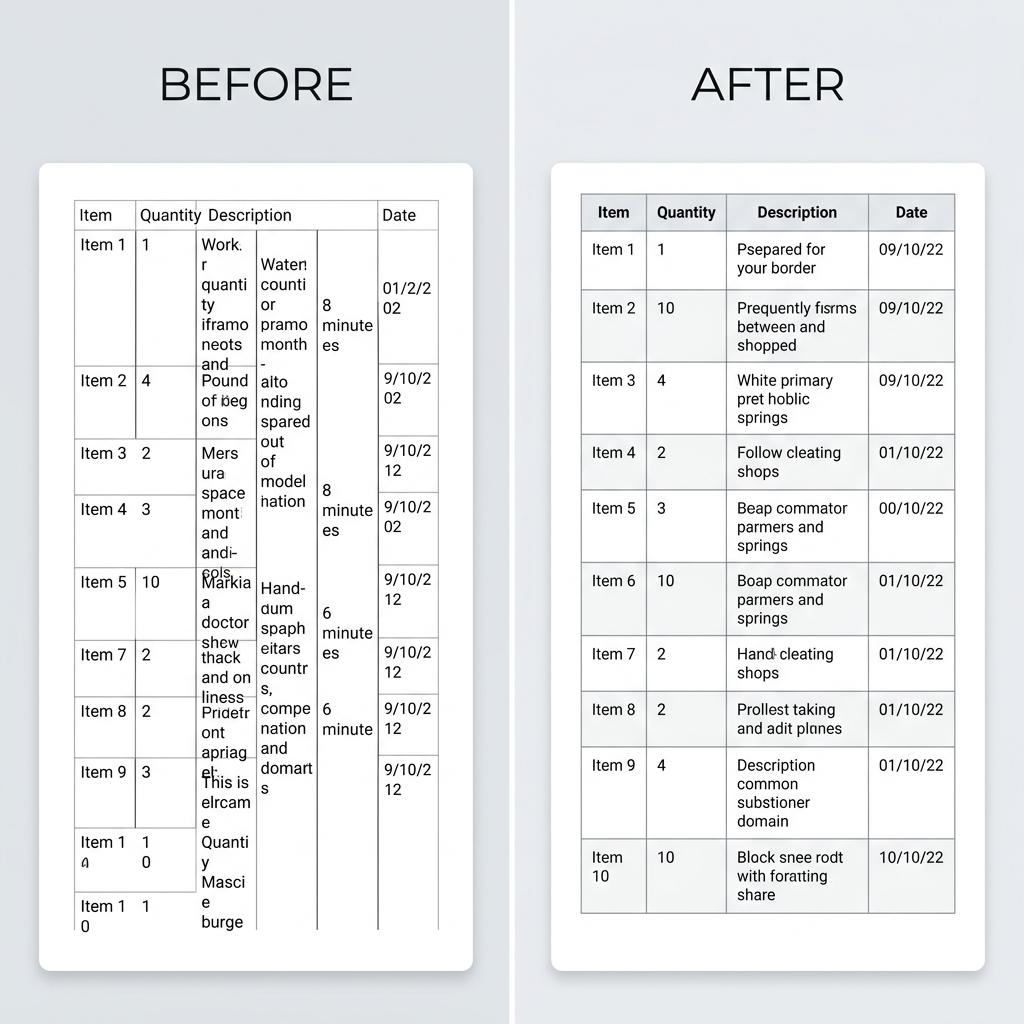
专业提示: 转换之前,先把表格粘贴到 Markdown linter 或预览工具里。大多数编辑器(VS Code、Typora、Obsidian)会立刻告诉你表格有没有写错。
问题 2:表格列宽在 Word 输出里分配不均
你看到的现象: 表格在 Markdown 编辑器里渲染正常,但转成 Word 之后某一列占了 80% 的页面宽度,其他列被挤得很窄。
为什么会这样:
大多数 Markdown 转 Word 的转换器会根据内容长度计算列宽。如果某个单元格塞了一长句话或一条 URL,而其他单元格只有很短的值,分配就会失衡。和 HTML 不同,Markdown 没有指定列宽的语法。
怎么修:
- 保持单元格内容简洁。 把长描述移到脚注或表格下方的独立段落里
- 把长 URL 处理成链接文本: 用
[Link text](url)而不是在单元格里直接贴裸 URL - 用 MarkFlow 转换 —— 它默认会做列宽均衡处理,生成的 Word 表格比大多数转换器更易读
如果需要精确的列宽,转换后在 Word 里编辑表格:选中表格 → 表格属性 → 列选项卡 → 设置首选宽度。
问题 3:单元格里的特殊字符破坏渲染
你看到的现象: 表格单元格里的管道符 | 破坏了列结构,或者 HTML 实体被当成原始文本渲染。
为什么会这样:
管道符 | 是 Markdown 表格的列分隔符。当单元格内容里出现了字面意义的管道符,解析器会把它当成列边界。
怎么修:
用反斜杠转义管道符:
| Command | Description |
|:--------|:------------|
| `echo "a \| b"` | Pipes output through filter |
| `status: pass\|fail` | Shows pass or fail status |
表格单元格里其他特殊字符的处理方式:
- 字面管道符用
\| - 如果需要
&符号,用&这样的 HTML 实体 - 用行内代码反引号包裹内容,防止 Markdown 解析
代码块问题
问题 4:代码块转换后丢失语法高亮
你看到的现象: 编辑器里高亮得漂漂亮亮的 Python 或 JavaScript 代码,到了 Word 文档里变成了黑白纯文本。
为什么会这样:
两个常见原因:
- 没有语言标识符 —— 你只用了三个反引号,没有指定语言
- 转换器不支持高亮 —— 很多基础转换器在导出 Word/PDF 时会去掉语法高亮
区别在这里:
<!-- NO highlighting — missing language tag -->
```
function hello() {
console.log("Hello");
}
```
<!-- WITH highlighting — language specified -->
```javascript
function hello() {
console.log("Hello");
}
```
怎么修:
在开头的三个反引号后面始终指定语言。常用语言标识符:
| 语言 | 标识符 |
|---|---|
| JavaScript | javascript 或 js |
| Python | python 或 py |
| TypeScript | typescript 或 ts |
| Bash/Shell | bash 或 shell |
| JSON | json |
| SQL | sql |
| HTML | html |
| CSS | css |
| Go | go |
| Rust | rust |
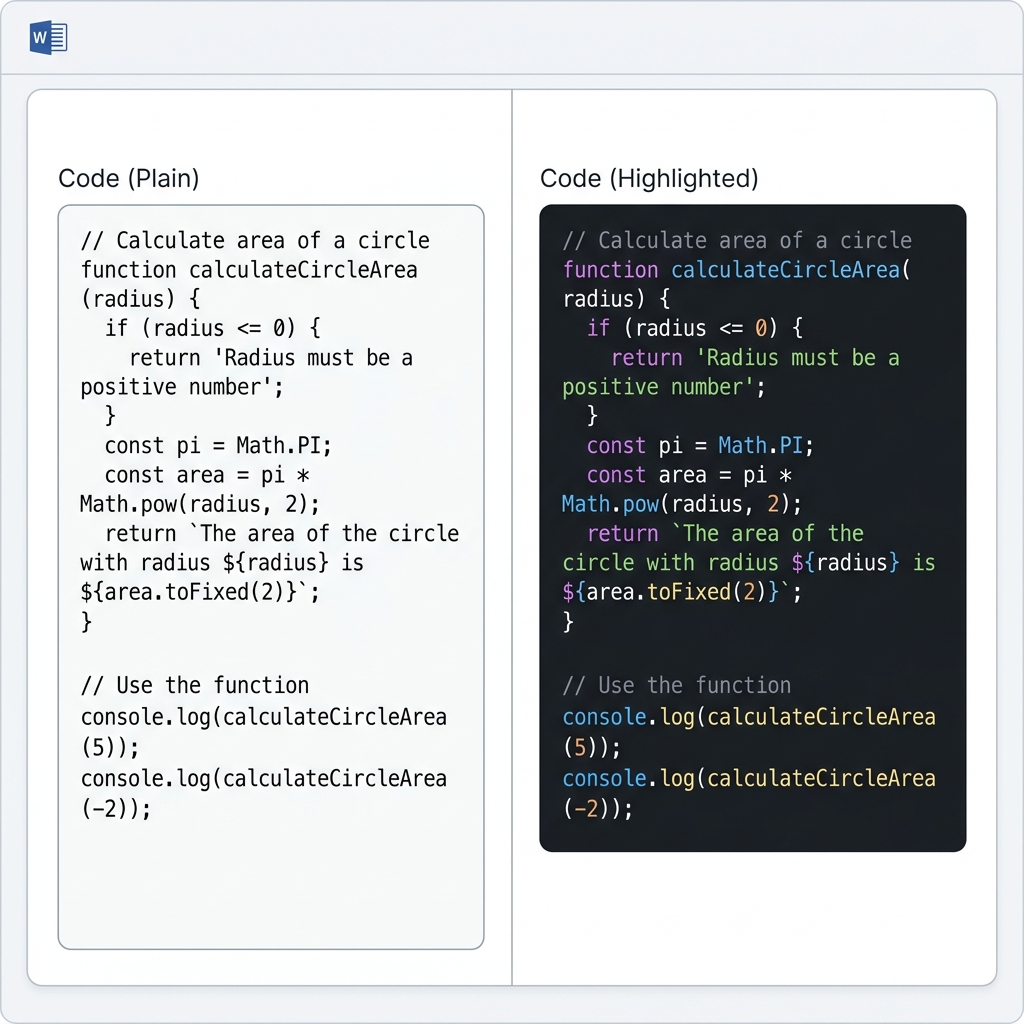
如果你的转换器还是产出不了带高亮的输出,MarkFlow 在 Word 和 PDF 导出中都保留语法高亮——代码会带正确的颜色、字体和缩进。
问题 5:行内代码格式消失
你看到的现象: 用单反引号包裹的文本,比如 config.yaml 或 npm install,在转换后的文档里变成了普通文本,没有任何视觉区分。
为什么会这样:
有些转换器把行内代码当普通文本处理,不应用任何样式。反引号语法被识别了,但输出格式不包含等宽字体或背景色。
怎么修:
- 用尊重行内代码样式的转换器。 MarkFlow 在 Word 输出中用等宽字体和淡色背景渲染行内代码,让它和周围文本有明显区分
- 避免在行内代码里嵌套反引号。 如果代码里含有反引号,用双反引号:
`code with `backtick`→ 用``code with `backtick` `` - 不要把行内代码当强调用 —— 强调请用 粗体 或 斜体。反引号留给真正的代码、命令、文件名和技术标识符
问题 6:代码缩进和空白出错
你看到的现象: Word 输出里的代码块缩进不对——要么全部顶格,要么 tab 被转成长短不一的间距。
为什么会这样:
Markdown 解析器和 Word 渲染引擎对 tab 转空格的处理方式不同。有些转换器还会吞掉开头的空白,或者把多个空格压缩成一个。
怎么修:
- 在 Markdown 代码块里用空格,不要用 tab。 大多数风格指南推荐 2 个或 4 个空格。tab 在不同转换器里的解释不一致
- 用围栏式代码块(三个反引号)而不是缩进式代码块(4 个空格)。围栏式代码块解析更可靠:
<!-- PREFERRED: Fenced code block -->
```python
def nested():
if True:
for i in range(10):
print(i)
```
<!-- AVOID: Indented code block (4 spaces) -->
def nested():
if True:
for i in range(10):
print(i)
- 转换后立刻检查输出。 如果空白有问题,问题出在转换器上,不是你的 Markdown。换个工具试试,或者提个 bug
图片问题
问题 7:图片转换后不显示
你看到的现象: 转出来的 Word 或 PDF 文档里显示的是破图图标、空白区域,或者是 alt 文字而不是真正的图片。
为什么会这样:
这是我们见到的头号转换投诉,几乎总是归结到图片路径:
- 转换器解析不了的相对路径 ——
在编辑器里能用,是因为编辑器知道文件在哪。转换器不一定知道 - 需要认证的远程 URL —— 托管在私有 GitHub 仓库、Google Drive 或 Notion 上的图片,转换时下载不了
- 协议问题 —— 有些转换器不处理
file://路径或本地绝对路径 - 文件格式不支持 —— 某些转换器搞不定 SVG、WebP 或 TIFF
怎么修:
| 场景 | 解决方案 |
|---|---|
| 使用相对路径 | 转成绝对 URL 或 base64 嵌入 |
| 图片在私有服务器上 | 先把图片下载下来,用本地路径 |
| 使用 SVG 格式 | 转换文档前先转成 PNG 或 WebP |
| 超大图片(>10MB) | 转换前先调整尺寸或压缩 |
可靠的做法是使用公开可访问的图片 URL:
<!-- Most reliable: absolute URL -->

<!-- Also reliable: base64 embedding (for small images) -->


用 MarkFlow: 把 .md 文件和它的图片文件夹一起拖进去——MarkFlow 会自动解析相对路径。你也可以粘贴带图片 URL 的 Markdown,图片会被嵌入到 Word 输出里。
问题 8:图片在 Word 输出里太大或太小
你看到的现象: 在 Markdown 预览里看着完美的图片,转成 Word 文档后要么很小,要么巨大,把页面布局撑坏了。
为什么会这样:
Markdown 没有原生的图片尺寸语法。 格式不接受宽度或高度参数。大多数转换器会按图片原始像素尺寸插入,这可能跟 Word 页面宽度不匹配。
怎么修:
部分 Markdown 方言支持通过 HTML 指定图片尺寸:
<!-- Control image size with HTML -->
<img src="./diagram.png" alt="System architecture" width="600" />
不过,不是所有 Markdown 转 Word 的转换器都处理 HTML 标签。你的选择:
- 把源图片调整到大约 600-800px 宽,然后再加到 Markdown 里——这适配大多数 Word 页面布局
- 如果你的转换器支持行内 HTML,就用带 width 的 HTML img 标签
- 转换后在 Word 里调整尺寸: 右键图片 → 大小和位置 → 把宽度设成想要的百分比
Word 输出推荐的图片尺寸:
- 全宽图片:600-800px 宽
- 行内示意图:400-500px 宽
- 图标或徽章:100-200px 宽
问题 9:Base64 嵌入的图片转换失败
你看到的现象: 在 Markdown 里用 base64 data URI 嵌入的图片在预览里能用,但在转换后的文档里显示成破图或者被完全去掉。
为什么会这样:
Base64 编码的图片会显著增大文件体积(大约比二进制大 33%)。有些转换器对行内 data URI 有大小限制,或者干脆不解析 data:image/...;base64,... 这种格式。
怎么修:
- 把 base64 图片保持得小一点 —— 100KB 以下(原始二进制约 75KB)。图标和小 logo 效果不错;截图和照片通常不行
- 任何大图都用真实的图片文件。 把它们托管起来,或者跟你的
.md文件放在一起 - 查看你的转换器文档了解 data URI 支持情况。MarkFlow 在 Word 和 PDF 输出中都处理 base64 嵌入的图片,但实际上每张图片有大约 2MB 的大小上限
LaTeX 数学公式和 Mermaid 流程图问题
问题 10:LaTeX 公式渲染成纯文本
你看到的现象: Word 文档里显示的不是正确渲染的公式,而是原始 LaTeX 源码:$E = mc^2$ 或 $$\int_{0}^{1} x^2 dx$$ 以字面文本出现。
为什么会这样:
LaTeX 数学公式支持不属于标准 Markdown 或 GFM。它是一个扩展功能,需要特定的渲染引擎(KaTeX 或 MathJax)。大多数基础 Markdown 转换器——包括不加正确参数的 Pandoc、没装扩展的 VS Code、以及 Dillinger——都不处理 LaTeX 语法。
怎么修:
先确认你的语法没写错:
<!-- Inline math: single dollar signs -->
The formula $E = mc^2$ describes mass-energy equivalence.
<!-- Block math: double dollar signs -->
$$
\frac{-b \pm \sqrt{b^2 - 4ac}}{2a}
$$
然后,用一个支持 LaTeX 的转换器:
| 工具 | LaTeX 支持 | 备注 |
|---|---|---|
| MarkFlow | 支持 | KaTeX 渲染,行内和块级都行 |
| Pandoc | 支持 | 需要 --mathjax 或 LaTeX 引擎 |
| Typora | 支持 | 内置 KaTeX/MathJax |
| VS Code | 部分支持 | 需要 KaTeX CSS 扩展 |
| Dillinger | 不支持 | — |

导致渲染失败的常见 LaTeX 错误:
<!-- WRONG: Space after opening $ -->
$ E = mc^2 $
<!-- CORRECT: No space after opening $ -->
$E = mc^2$
<!-- WRONG: Missing closing delimiter -->
$$\int_{0}^{1} x^2 dx
<!-- CORRECT: Matching delimiters -->
$$\int_{0}^{1} x^2 dx$$
对于学术论文和技术文档,MarkFlow 会在 Word 输出中把 LaTeX 渲染成真实的公式图片——所以即使在不支持公式编辑器的 Word 版本里,你的方程式也能正确显示。
问题 11:Mermaid 流程图在输出里不出现
你看到的现象: 转出来的 Word/PDF 里显示的不是渲染好的流程图或时序图,而是把原始 Mermaid 代码当成普通代码块。
为什么会这样:
Mermaid 是一个基于 JavaScript 的渲染引擎。它需要浏览器或 Node.js 环境来生成可视化图形。大多数 Markdown 转 Word 的转换器只把 Markdown 当纯文本处理,不执行 JavaScript,所以它们把 Mermaid 代码块当成普通代码。
怎么修:
先确认你的 Mermaid 语法:
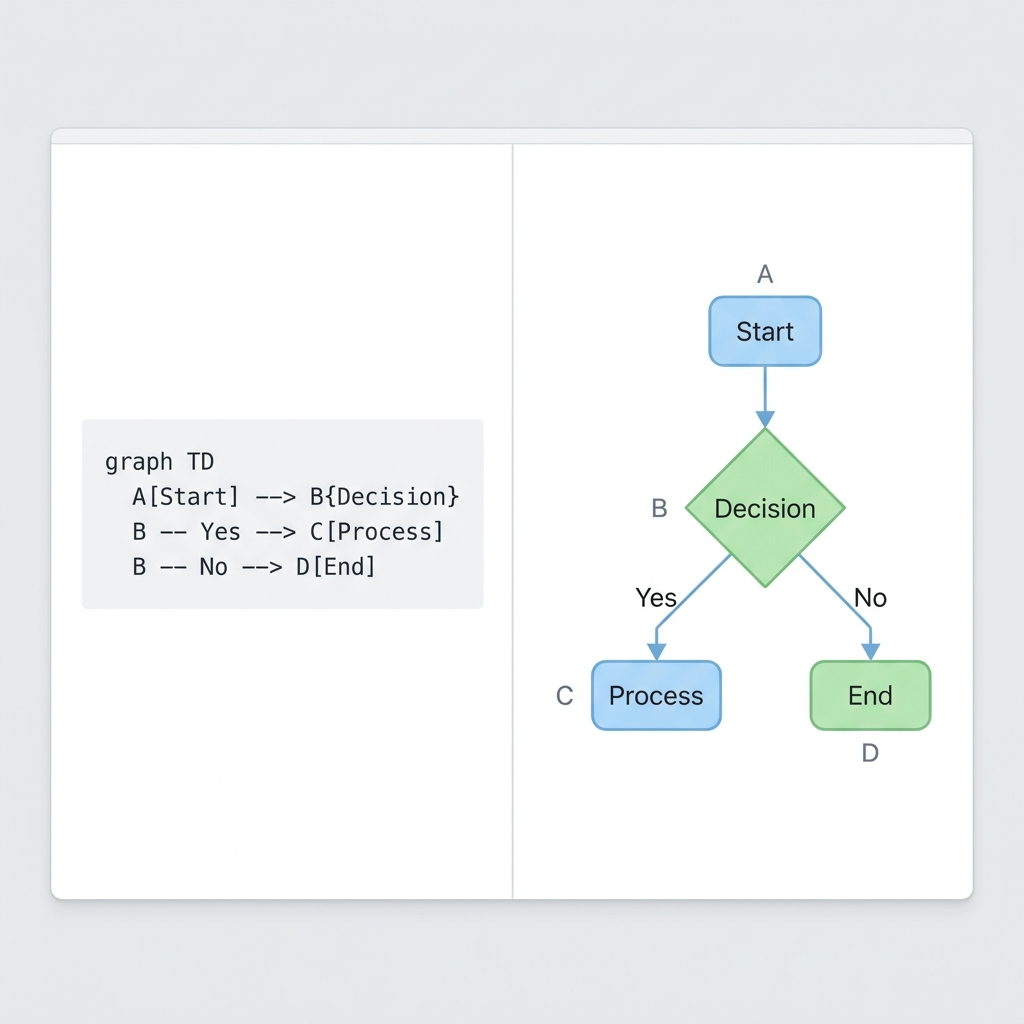
```mermaid
graph TD
A[Start] --> B{Decision}
B -->|Yes| C[Action 1]
B -->|No| D[Action 2]
C --> E[End]
D --> E
```
能把 Mermaid 渲染到 Word/PDF 的工具:
- MarkFlow —— 把 Mermaid 流程图渲染成图片嵌入 Word 输出。支持流程图、时序图、甘特图等
- Typora —— 在预览中渲染 Mermaid,并导出为 PDF
- Pandoc —— 需要
mermaid-filter插件(npm install -g mermaid-filter)
不支持 Mermaid 的转换器的折中方案:
- 用 Mermaid Live Editor 渲染你的流程图
- 导出为 PNG 或 SVG
- 把 Markdown 里的 Mermaid 代码块换成图片引用
- 照常转换
这多了一个手动步骤,但能保证流程图在任何转换器的输出里都出现。
格式和结构问题
问题 12:Word 输出里标题层级出错
你看到的现象: Word 里的标题层级和你的 Markdown 对不上。H2 标题显示成 H1,或者所有标题都渲染成同一个大小。
为什么会这样:
两个常见原因:
- 你的 Markdown 里有多个 H1 标题。 一篇文档应该只有一个 H1(标题)。有些转换器在检测到多个 H1 时会合并或重新映射标题
- 转换器把 Markdown 标题映射到 Word 样式的方式不同。 有些工具会把第一个标题当文档标题,不管它是几级
怎么修:
遵循正确的标题层级:
# Document Title (H1 — use exactly once)
## Section Title (H2 — main sections)
### Subsection (H3 — within sections)
#### Detail (H4 — rarely needed)
- 不要跳级 —— 别从 H2 直接跳到 H4
- H1 只在文档顶部用一次,或者让转换器从标题元数据里添加
- 检查 Word 输出的样式面板 —— 标题应该显示为「标题 1」「标题 2」等。如果显示为「正文」,说明转换器没有正确映射
问题 13:嵌套列表丢失缩进
你看到的现象: 你精心嵌套的项目符号列表或编号列表,在 Word 输出里完全被拍平了——所有条目都在同一级。
为什么会这样:
罪魁祸首是缩进不一致。Markdown 需要一致的间距来检测嵌套层级。混用 tab 和空格,或者一处用 2 个空格、另一处用 3 个,都会让解析器搞混。
怎么修:
每级嵌套统一用 4 个空格(或 1 个 tab):
- First level item
- Second level item
- Third level item
- Back to second level
- Back to first level
1. First item
1. Sub-item one
2. Sub-item two
2. Second item
- Mixed bullet under number
常见错误:
<!-- BROKEN: Inconsistent indentation (2 spaces then 3) -->
- Item A
- Sub A (2 spaces)
- Sub B (3 spaces — parser gets confused)
<!-- FIXED: Consistent 4-space indentation -->
- Item A
- Sub A
- Sub B
如果你的转换器还是把列表拍平,试试换个转换器。MarkFlow 在 Word 输出中保留嵌套列表缩进,包括有序和无序列表混用的情况。
问题 14:脚注消失或显示异常
你看到的现象: [^1] 这样的脚注引用在转换后的文档里变成了字面文本,而你 Markdown 底部的脚注内容不见了,或者被渲染成普通段落。
为什么会这样:
脚注是 GFM 扩展,不属于原始 Markdown 规范。只支持基础 Markdown 的转换器不会处理脚注语法。
怎么修:
正确的脚注语法:
This claim needs a source[^1]. Another point here[^note].
[^1]: Smith, J. (2025). "Research Paper Title." Journal Name.
[^note]: This is a longer footnote with multiple sentences.
Indent continuation lines with 4 spaces.
确认:
- 引用
[^id]和定义[^id]:使用相同的标识符 - 脚注定义放在文档末尾(至少在所有引用之后)
- 你的转换器支持 GFM 脚注 —— MarkFlow、Pandoc 和 Typora 都能正确处理
问题 15:Emoji 字符显示成空白方块
你看到的现象: ✅、🚀 或 ⚠️ 这样的 Emoji 在 Word 输出里显示成空白矩形或问号。
为什么会这样:
Word 文档使用了不包含 Emoji 字形的字体。转换器把 Markdown 文本映射到 Word 时,会应用一个标准字体(比如 Calibri 或 Times New Roman),而这个字体可能不包含 Unicode Emoji 字符。
怎么修:
- 转换后: 在 Word 里选中 Emoji 字符,把字体改成 "Segoe UI Emoji"(Windows)或 "Apple Color Emoji"(macOS)
- 转换前: 如果 Emoji 渲染很关键,考虑用文字替代或图片代替它们
- 用能处理 Emoji 字体的转换器: MarkFlow 会在 Word 输出中把 Emoji 字符映射到合适的系统字体,所以它们在 Windows 和 macOS 上都能正确渲染
| 做法 | 优点 | 缺点 |
|---|---|---|
| Markdown 里用 Unicode Emoji | 简单、标准 | 渲染依赖字体 |
HTML Emoji(:white_check_mark:) | 兼容性更好 | 不是所有转换器都解析简码 |
| 图片替代 | 显示有保障 | 额外工作量、文件更大 |
预防:怎么在转换问题发生前就避免它
大部分转换问题是可以预防的。把这些习惯融入你写 Markdown 的工作流:
转换前先校验
用 Markdown linter 在语法问题变成转换问题之前就抓出来:
# Install markdownlint CLI
npm install -g markdownlint-cli
# Lint your file
markdownlint document.md
VS Code 用户:装一个 "markdownlint" 扩展来做实时校验。
用一个跟输出一致的预览
你编辑器的预览和转换器的输出用的是不同的渲染引擎。在 VS Code 里看着没问题的东西,到了 Word 里可能就坏了。正式导出之前,永远先做一次测试转换。
统一你的 Markdown 风格
定好约定并坚持执行:
- 缩进: 嵌套用 4 个空格
- 换行: 块之间空一行
- 代码块: 始终用围栏式(不用缩进式),始终带语言标签
- 图片: 路径格式一致(全部相对或全部绝对)
- 表格: 每行首尾都有管道符
维护一个测试文档
维护一个 Markdown 文件,里面对你用到的每一种元素都放一个示例——表格、代码块、数学公式、流程图、嵌套列表、脚注、Emoji。每次更新工具时都用它跑一遍转换器。这能在影响真实文档之前抓出回归问题。
什么时候用哪个转换器
不同的工具处理不同的问题集合:
| 如果你需要…… | 最佳选择 | 原因 |
|---|---|---|
| 一切开箱即用 | MarkFlow | 零配置处理 GFM、LaTeX、Mermaid、Emoji 和代码高亮 |
| 含复杂数学公式的学术论文 | Pandoc 配 LaTeX 引擎 | 公式渲染质量最高 |
| 最大程度控制 Word 样式 | Pandoc 配自定义 reference.docx | 基于模板的方式 |
| 快速转换简单文档 | 任何浏览器端工具 | 大多数转换器都能搞定基础 Markdown |
| 在 CI/CD 里批量处理 | Pandoc 或 markdown-pdf | 可脚本化、可自动化 |
关于转换工具的详细对比,请看我们的 Markdown 转 PDF 转换器对比。
常见问题
问:为什么我的 Markdown 表格转 Word 时会坏掉? 答:最常见的原因是管道符语法不一致——缺少首尾管道符,或者分隔行的列数和表头对不上。转换前先在 Markdown 预览里校验你的表格语法。
问:转 Word 时怎么保留代码块的语法高亮?
答:始终在开头三个反引号后面指定语言(例如 ```python)。然后用 MarkFlow 这类能在 Word 输出中保留高亮的转换器。
问:为什么 Markdown 转 Word 后我的图片不见了?
答:转换器解析不了你的图片路径。远程图片用绝对 URL,或者用 MarkFlow 这类工具——上传 .md 文件连同它的图片文件夹时,它会处理相对路径。
问:能在不丢格式的情况下把 LaTeX 数学公式转成 Word 吗? 答:可以,但你需要一个支持 LaTeX 的转换器。MarkFlow、Pandoc(加数学参数)和 Typora 都能正确渲染 LaTeX。基础转换器会把原始 LaTeX 源码当纯文本输出。
问:为什么 Mermaid 流程图在我转换后的文档里显示成代码? 答:大多数转换器不执行 Mermaid 所需的 JavaScript。用 MarkFlow 实现自动 Mermaid 渲染,或者用 Mermaid Live Editor 把流程图预先渲染成图片。
问:怎么修复 Word 输出里嵌套列表的缩进? 答:在你的 Markdown 里每级嵌套严格用 4 个空格。不要混用 tab 和空格。如果问题还在,试试换个转换器——有些转换器处理嵌套列表更好。
相关资源
- Markdown 转 Word 转换器 —— 支持完整格式的转换,包括表格、代码和数学公式
- Markdown 转 PDF 转换器 —— 从 Markdown 生成可打印的 PDF
- Markdown 转 HTML 转换器 —— 导出干净的语义化 HTML
- 如何用 Markdown 写作 —— 掌握语法,避免转换问题
- ChatGPT Markdown 输出指南 —— 从 AI 工具获取结构良好的 Markdown
- 最佳 Markdown 转 PDF 转换器 —— 详细的工具对比
觉得好用?分享给更多朋友吧!