DeepSeek を Word に変換:数式・コード・中国語も完璧 2026
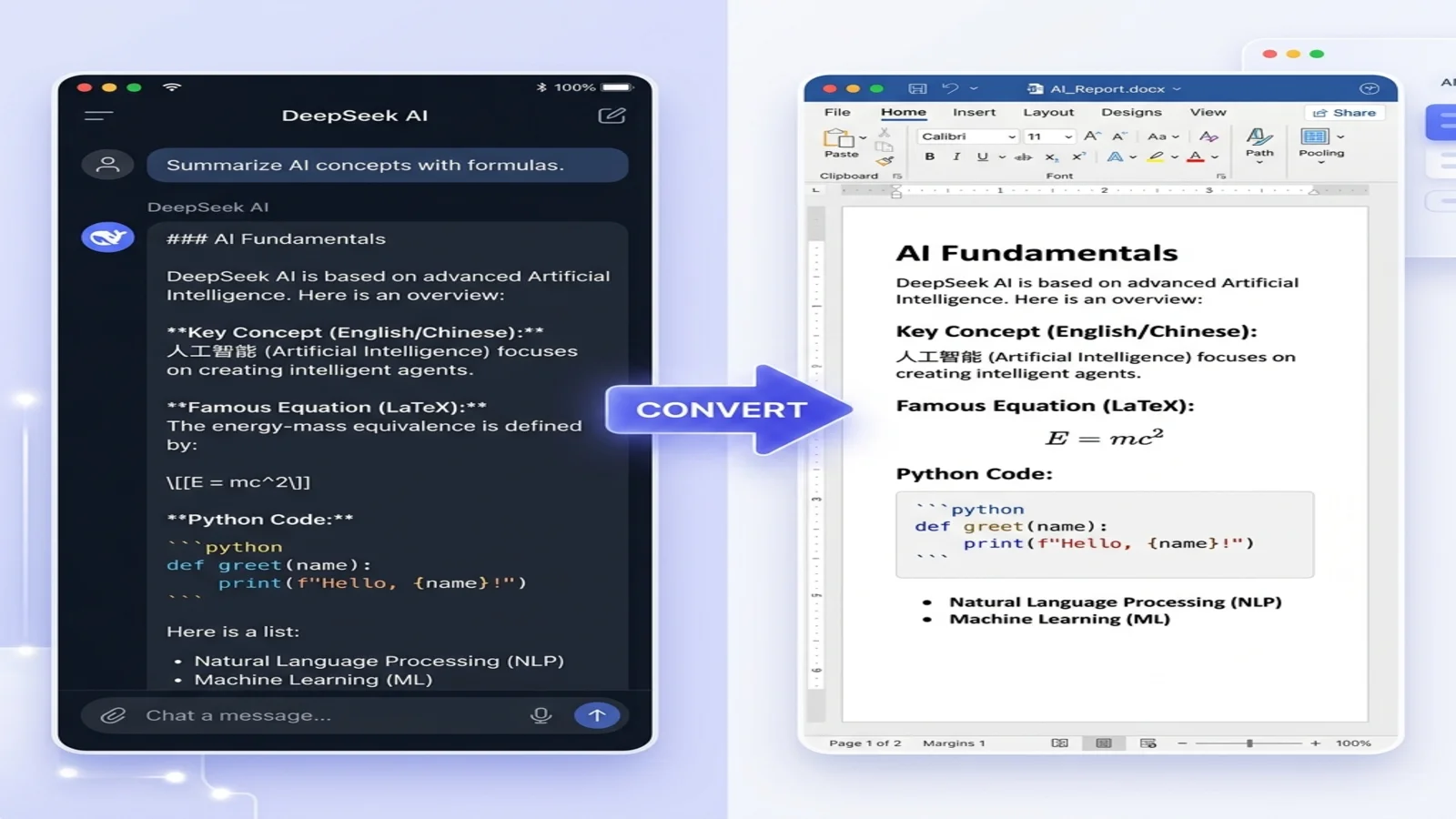
DeepSeek に数式の証明や中英バイリンガルのリサーチノートを書かせました。チャット画面では出力が美しく見えます。ところが Word に貼り付けた瞬間、すべてが崩壊していくのを目にします——LaTeX 数式は $$ 記号の羅列に、中国語は空の四角に、コードブロックはインデントの痕跡をすべて失います。20 分かけて修正しながら、「2026 年にもなってまだこんなに大変なのか」と思ったはずです。
解決策はもう 1 つの整形プラグインではありません。DeepSeek が最初に渡してくる形式そのものを変えることです。DeepSeek に Markdown を頼み、その Markdown を直接 Word に変換すれば、数式は編集可能なまま、中国語はくっきり、コードは整形されたままになります。
なぜ Markdown ワークフローが勝つのか
DeepSeek の出力を直接 Word に貼り付けるのと、Markdown を経由するのとでは、まったく異なる結果になります——特に DeepSeek が得意とする数式・コード・バイリンガルコンテンツでは顕著です。2 つのアプローチを比較すると:
| 観点 | 直接コピー&ペースト | Markdown ワークフロー |
|---|---|---|
| 修正の手間 | 貼り付けるたびに手作業で修正 | 変換してダウンロード——修正なし |
| LaTeX 数式 | $$E=mc^2$$ の生テキストとして貼り付く | 編集可能な Word ネイティブ数式 |
| 中国語文字 | しばしば空の四角(□□□) | 適切なフォントフォールバックで正しく描画 |
| Python コードブロック | インデント消失、等幅フォントなし | 等幅フォント、インデント保持 |
| テーブル | 罫線崩れ | きれいな Word ネイティブテーブル |
このガイドでは、ワークフロー全体・DeepSeek が最も得意とする要素・そして「変換しやすい Markdown」を引き出すプロンプトを順に解説します。
クイックスタート:DeepSeek を Word に変換する 3 ステップ
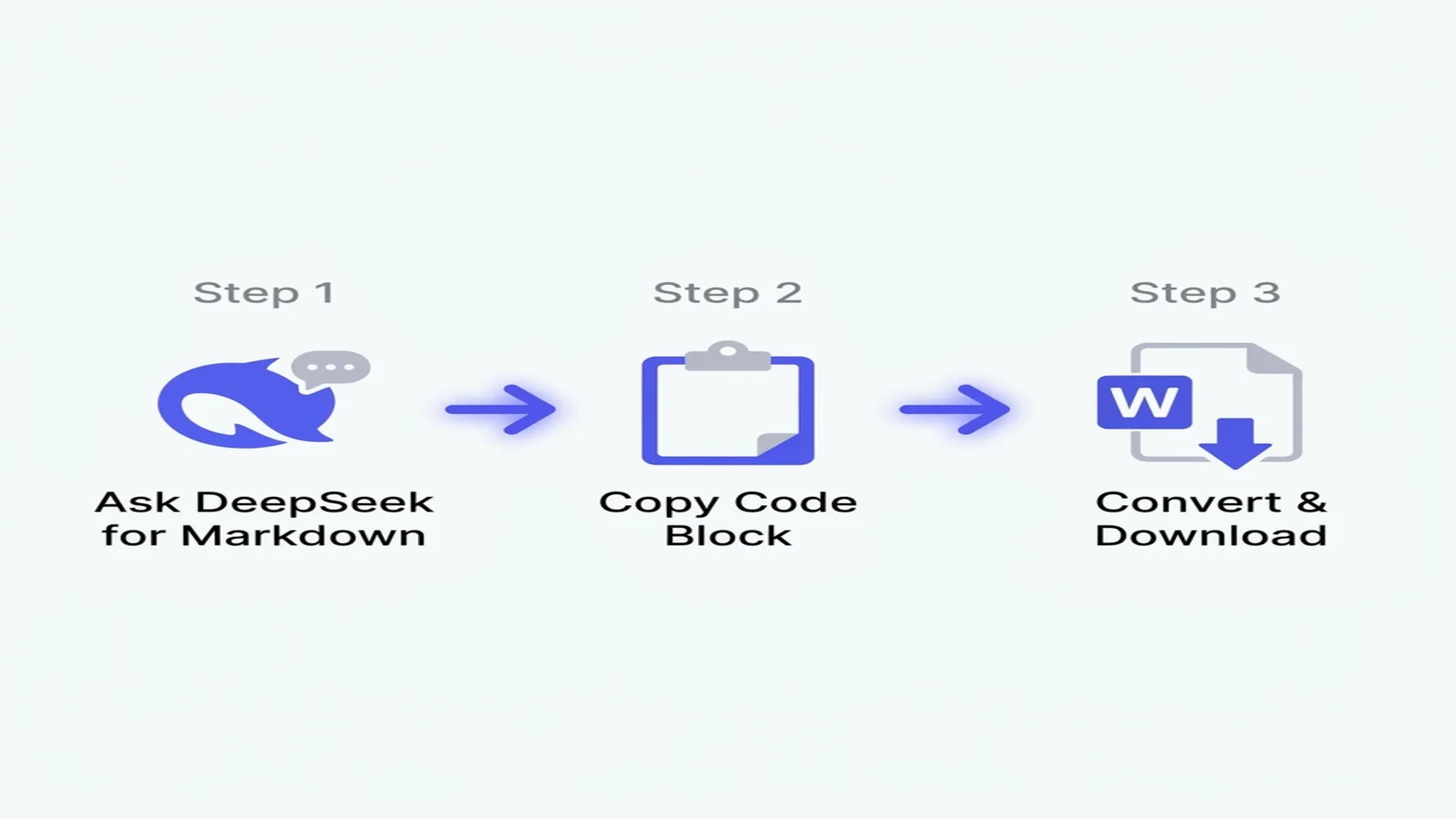
60 秒しかない場合:
- DeepSeek のプロンプトに「Markdown 形式で出力して」と追加——回答全体がコピー可能なコードブロックに収まります。
- 回答右上の「Copy code」ボタンを押す(テキストを手動で選択しない)。
- 無料コンバーターに貼り付けて DOCX をダウンロード——数式・コード・中国語、すべて維持されます。
これでワークフロー全体は完了です。以下の内容は、DeepSeek の出力がさらに複雑になるケース(数式の多い推論チェーン、英中混在ドキュメント、長いコードブロック)への対応です。
なぜ直接コピーすると DeepSeek の出力が崩れるのか
DeepSeek のチャット画面は HTML と CSS で描画されています——数式は KaTeX、コードはシンタックスハイライトライブラリ、中国語はシステムフォント。テキストを選択してコピーすると、ブラウザは雑多な HTML・インラインスタイル・フォント参照をクリップボードに渡し、Word のクリップボードパーサはそれを正しく解釈できません。
頻発する 3 つの失敗パターン:
- LaTeX 数式が生テキストとしてペーストされる。
$$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$が、描画された数式ではなくそのまま文字として出てしまいます。DeepSeek-R1 の出力は数式表記を多用するため、特に致命的です。 - 中国語文字が壊れたフォントにフォールバックする。 元のフォントが Word にない場合、文字は
□の四角や代替グリフになります。これでは共有しようとしていたバイリンガル文書が台無しです。 - コードブロックのインデントが全て消える。 Python の
defブロックが 1 行に潰れ、シンタックスハイライトが消え、等幅フォントが Calibri に戻ります。
Markdown はこれらをすべて回避できます。Markdown は意味的なマーカーが付いたプレーンテキストだからです。Word コンバーターはこのマーカーを読み取り、それぞれを Word のネイティブ機能にマッピングできます:$$...$$ は Word 数式に、フェンスドコードブロックは整形済みコード段落に、中国語文字はフォント乗っ取りなしに Unicode として挿入されます。
DeepSeek から Word へ、Markdown が最適なブリッジである理由
DeepSeek の学習データは GitHub・arXiv・技術ドキュメントに大きく偏っています——いずれもネイティブで Markdown を使います。そのため、技術コンテンツに関しては ChatGPT や Gemini よりもクリーンな、仕様準拠の Markdown をデフォルトで生成します。
Word ワークフローでは特にこの 3 つの特性が効きます:
- 数式が一級市民。 DeepSeek は LaTeX を
$$...$$の区切り文字で出力するため、まともなコンバーターはこれを検出して Word OMML(Office Math Markup Language)に変換できます。 - バイリンガルが崩れない。 Markdown はフォント参照を埋め込まないので、コンバーターは Word のデフォルト東アジアフォント(多くのシステムでは SimSun または Microsoft YaHei)を競合なく適用できます。
- コードブロックに言語タグが付く。
```pythonや```rustは変換後も保持され、必要なら下流ツールがハイライトを再適用できます。
DeepSeek の出力を Word に手動で貼り付けていたなら、このワークフローはその繰り返しの修正作業の大半をなくしてくれます。
ステップバイステップ:DeepSeek から Word へ
1:DeepSeek に Markdown 出力をリクエスト
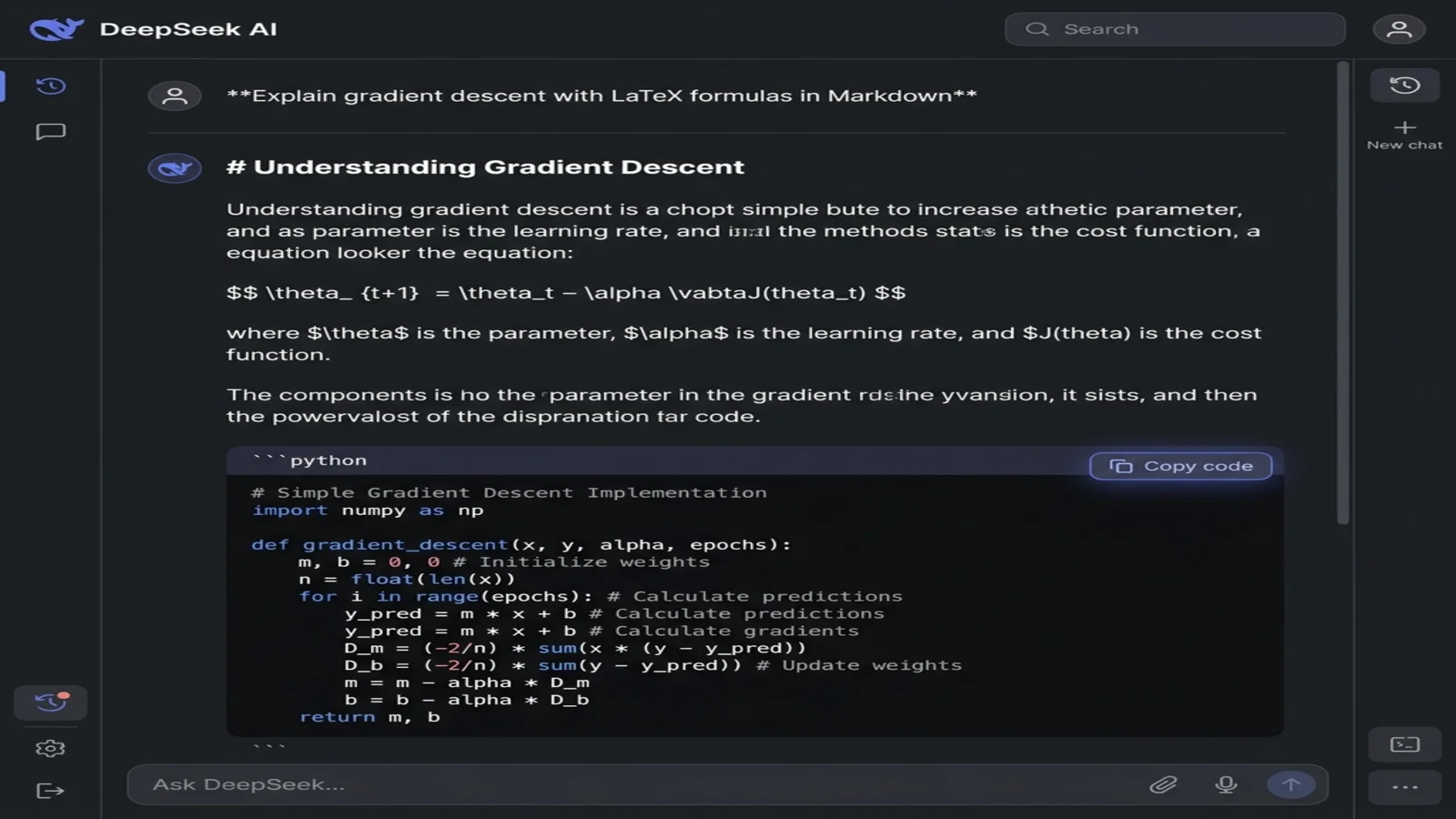
プロンプトの書き方で、DeepSeek が返すのが「描画済み HTML」か「生 Markdown」かが決まります。一文足すだけで解決します:
汎用プロンプト(描画済み出力、きれいにコピーしにくい):
勾配降下法を数式と Python の例で説明して
Markdown 対応プロンプト(クリーンなコードブロックを返す):
勾配降下法を Markdown 形式で説明してください。要件:
- セクション分けに H2・H3 見出しを使用
- 数式は $$...$$ の LaTeX で記述
- Python の例はフェンスドコードブロックで
- 末尾に要約テーブルを追加
DeepSeek は純粋な Markdown を含む 1 つのコードブロックで返します——見出しは #、数式の周りは $$、コードの周りはバックティック 3 つのフェンス。描画版ではなくマークアップ自体が見えるはずで、それがまさに欲しい状態です。
R1(推論モデル)向けの Tips: DeepSeek-R1 は最終回答の前に長い思考連鎖のセクションを出力します。成果物だけが必要なら、最終回答だけを Markdown で出力。思考プロセスは出力しない と添えてください。
2:Markdown コードブロックをコピー
回答エリアの右上を見てください。DeepSeek はコードブロックごとに**「Copy code」**ボタン(クリップボードのアイコンの場合もあり)を表示します。これをクリックします。
重要:テキストを手動で選択してコピーしないでください。 手動選択は DeepSeek の CSS スタイルまで拾ってしまい、それこそが Word を崩壊させるノイズです。「Copy code」ボタンが返すのは純粋なプレーンテキストの Markdown——コンバーターが欲しいのはそちらのバージョンです。
DeepSeek の回答が複数のコードブロックに分かれている場合は、それぞれをコピーし、変換前にプレーンテキストエディタで連結してください。
3:Word に変換
- MarkdownToWord.pro を開く
- Markdown を入力エリアに貼り付け
- 「Convert to Word」をクリック
- DOCX ファイルをダウンロード
変換はわずか数秒で完了し、アカウントは不要です。あなたのコンテンツは変換を実行するためだけに使われ、その直後に削除されます——保存されることはありません。
DeepSeek の最強要素への対応
LaTeX 数式(DeepSeek-R1)

DeepSeek の推論モデル(R1)は、入手可能なオープンモデルの中でも最も数学に強いモデルの 1 つです。明示的に頼まなくても LaTeX を頻繁に使います。その数式を確実に Word まで届けるために:
LaTeX を明示的にリクエスト:
二次方程式の解の公式を Markdown で 1 ステップずつ導出してください。
ディスプレイ数式は $$...$$、インライン数式は $...$ を使ってください。
DeepSeek はこのように返します:
二次方程式は $ax^2 + bx + c = 0$ です。
平方完成で解くと:
$$x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}$$
変換後は、インラインの $ax^2 + bx + c = 0$ が Word のインライン数式に、ディスプレイ数式が中央揃えで完全編集可能な Word 数式になります。Word で数式をクリックすれば数式エディタが開き、変数を変えたり、ステップを追加したり、PowerPoint にコピーすることもできます。
よくある問題: 数式が変換後にプレーンテキストで表示される場合、DeepSeek が $$ 区切り文字を使ったか、それとも Unicode の数学記号を使ったか確認してください。Unicode 文字ではなく LaTeX 区切り文字 $$...$$ を使ってください と再プロンプトできます。
中国語と英中バイリンガル文書
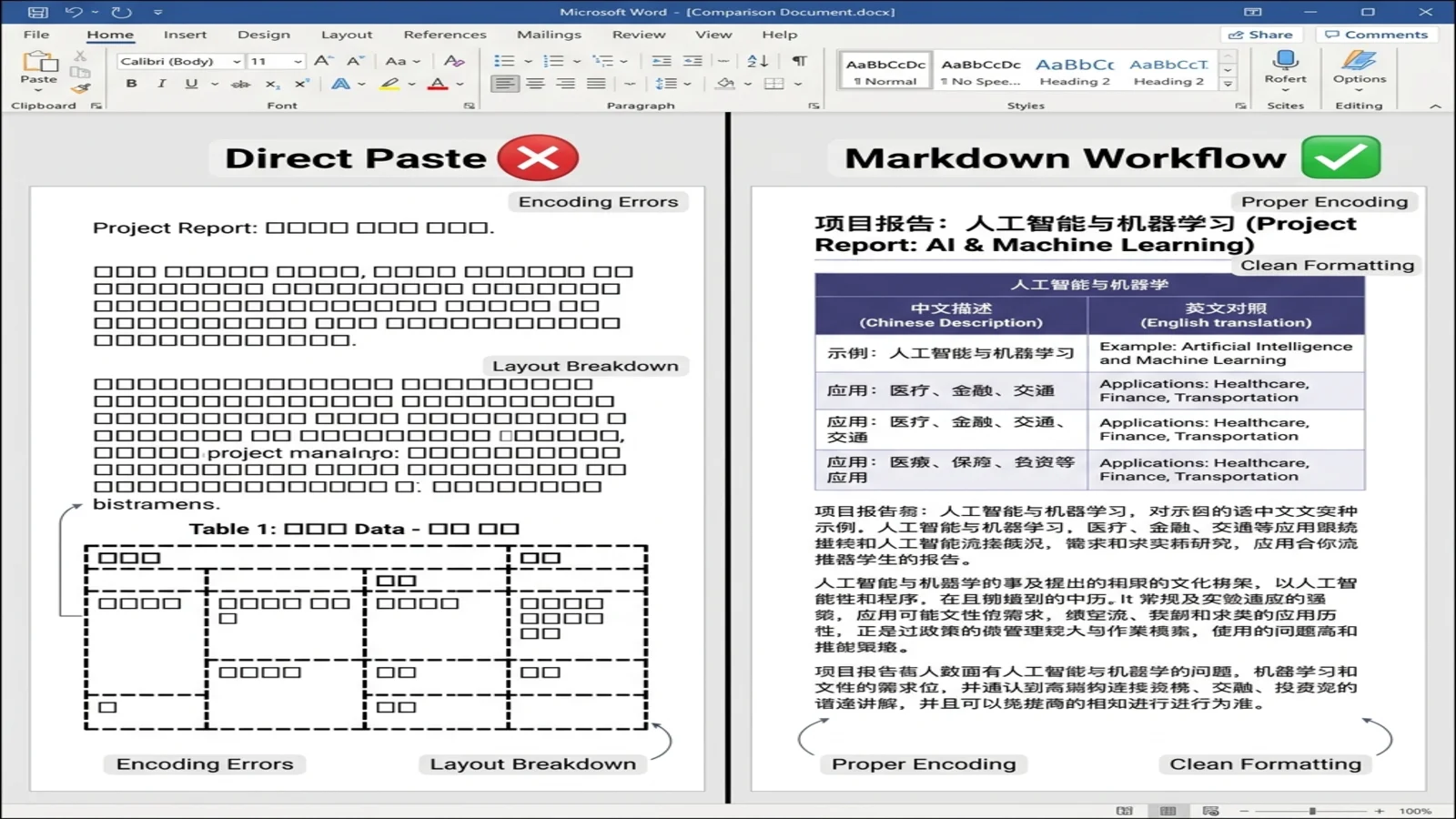
DeepSeek は、中国語コンテンツで深く学習された数少ないフロンティアモデルの 1 つです。そのバイリンガル出力品質は、クロスボーダーチームや技術翻訳、学術ライティングに本当に役立ちます。Markdown ワークフローはこの強みを完全に保ちます。
バイリンガル出力のクリーンなプロンプト:
製品仕様書を Markdown で書いてください。バイリンガル列で出力:
- 左列:英語
- 右列:簡体字中国語(简体中文)
Markdown テーブルで表現してください。
DeepSeek は次のように返します:
| Feature | English | 中文 |
|---------|---------|------|
| Storage | 5 GB free tier | 5 GB 免费额度 |
| Users | Unlimited | 无限制 |
| Support | Email & chat | 邮件与在线客服 |
変換後、Word は両言語ともきれいで揃ったテーブルとして描画します。Word は自動的にデフォルトの東アジアフォント(多くのシステムでは SimSun や Microsoft YaHei)にフォールバックするため、手動のフォント調整は不要です。
繁体字中国語向け Tips: プロンプトに「繁體中文 (Traditional Chinese)」と指定してください。DeepSeek は両方の文字体系をうまく扱いますが、指定しなければデフォルトは簡体字です。
コードブロック(Python・Rust・JavaScript・SQL)
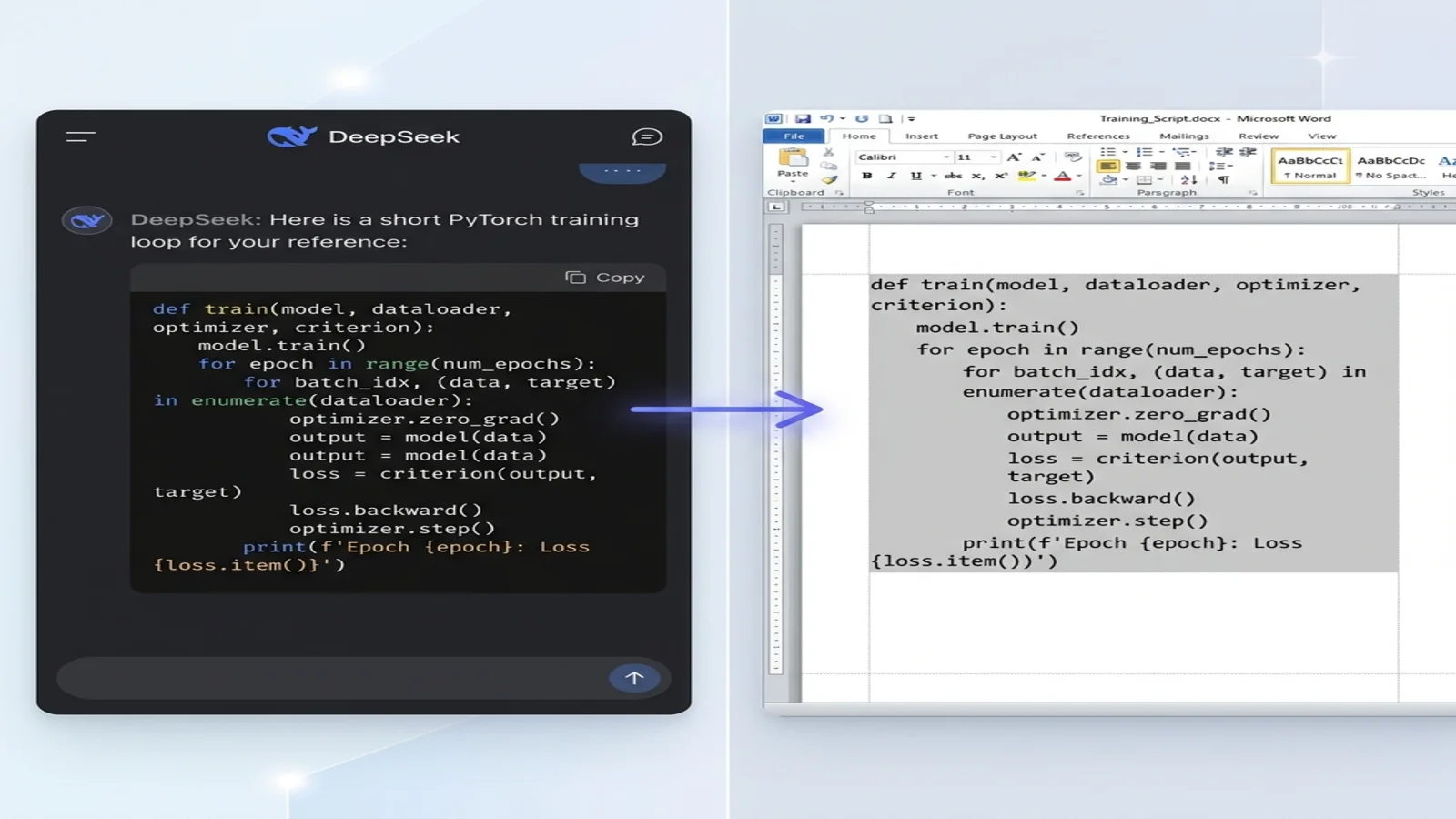
DeepSeek-Coder は開発者向けの派生モデルで、すべての LLM の中でも最もクリーンなコード出力を生成します。Word に変換しても本当に読めるコードにするために:
必ずコードの言語をタグ付け:
PyTorch の学習ループを Markdown で見せてください。
python の言語タグを付けたフェンスドコードブロックを使ってください。
DeepSeek は次のように返します:
```python
def train(model, dataloader, optimizer, loss_fn):
model.train()
for batch in dataloader:
optimizer.zero_grad()
loss = loss_fn(model(batch.x), batch.y)
loss.backward()
optimizer.step()
return model
```
Word への変換後:
- コード段落は Consolas(またはシステムの等幅フォント)
- 4 スペースのインデントが正確に保持される
- 背景に薄いグレーのシェーディングが入り、本文と区別される
- 行が文の途中で不自然に折り返されない
技術ドキュメントで本文とコードを混在させるなら、この 1 つの変更だけで Word が再び実用的な出力フォーマットになります。
テーブルと比較マトリクス
DeepSeek のテーブル出力は GitHub Flavored Markdown(GFM)準拠です。列名を伝えれば、きれいなパイプ構文のテーブルを作ります:
| Model | Parameters | Context Window | License |
|-------|-----------|----------------|---------|
| DeepSeek-V3 | 671B | 128K | MIT |
| DeepSeek-R1 | 671B | 128K | MIT |
変換後は Word ネイティブテーブル——セルが編集可能、罫線がきれい、列がきちんと揃っています。手動で列のずれを直す必要はもうありません。
試してみる
ワークフローも差別化ポイントもお見せしました。アクションプラン:
- このページをブックマーク——プロンプトのパターンをワンクリックで参照可能に。
- 次回の DeepSeek セッションで 3 ステップを試す——一番の「おっ」を見たいなら、数式が多い題材から始めてください。
- DeepSeek を Word に手動コピーしているチームメイトと共有してください。
あなたの DeepSeek Markdown を今すぐ変換
無料・高速・登録不要。
開発者向け:DeepSeek から Word への変換の仕組み
クリックして展開:数式・コード・中国語の変換パイプライン
なぜ DeepSeek の Markdown はこれほど確実に変換できるのか
DeepSeek の学習コーパスは arXiv 論文・GitHub リポジトリ・中国語の技術フォーラムに大きく偏っており、いずれも構造化された Markdown を生成します。下流の変換に対して特に有利な 3 つの特性:
- CommonMark 準拠。 DeepSeek は一貫して
#見出し(===下線ではない)、フェンスドコードブロック(インデント形式ではない)、パイプテーブルを使用——主流のパーサがネイティブで扱えるすべての GFM 拡張です。 - 安定した LaTeX 区切り文字。 ディスプレイ数式は
$$...$$、インライン数式は$...$をデフォルトで使用——主要な Markdown→DOCX ライブラリ(pandoc、docx-templates、mdast-util-to-docx)はいずれも認識します。 - コードブロックの言語タグ。
```python、```rust、```sqlは変換後も保持され、必要に応じてレンダラーがシンタックスハイライトを再適用できます。
変換パイプライン
コンバーターには 4 つの仕事があります:
1. トークン化。 markdown-it、marked、または remark を使い、Markdown を抽象構文木(AST)にパース。各見出し・段落・数式・コードブロックがノードになります。
2. AST → DOCX マッピング。 AST を辿り、各ノードに対して Office Open XML(OOXML)を出力:
| Markdown | OOXML 要素 |
|---|---|
# Heading | <w:pStyle w:val="Heading1"/> |
**bold** | <w:b/> |
| コードブロック | 段落 + <w:shd> シェーディング + 等幅フォント |
$$...$$ | <m:oMath> ブロック |
3. 数式処理(LaTeX → OMML)。 ここで DeepSeek の出力が最も恩恵を受けます。$$...$$ 内の LaTeX をパース(通常 mathjax-node や temml)して、Office Math Markup Language として出力:
<m:oMath>
<m:f>
<m:num><m:r><m:t>-b ± √(b² − 4ac)</m:t></m:r></m:num>
<m:den><m:r><m:t>2a</m:t></m:r></m:den>
</m:f>
</m:oMath>
結果は Word の数式エディタで開ける、完全編集可能なネイティブ数式です——フラットな画像ではありません。
4. CJK フォントフォールバック。 中国語の文字は、Word が正しいフォントを選べるよう、OOXML で東アジアフォントを明示的に指定する必要があります:
<w:rPr>
<w:rFonts w:ascii="Calibri" w:eastAsia="SimSun"/>
</w:rPr>
良いコンバーターは入力中の漢字を検出して、この run プロパティを自動注入します。
パフォーマンスについて
変換速度はいくつかの段階に左右されます:
- Markdown を AST にパースするのは高速で、ボトルネックになることはほとんどありません。
- DOCX の組み立て——OOXML 構造の構築——はドキュメントの長さとともに増えます。
- 数式レンダリングは通常最もコストの高いステップで、数式が多いドキュメントはテキストのみのものより明らかに長くかかります。
典型的なドキュメントなら、全体のプロセスは依然として数秒で完了します。数式が数百あるドキュメントはより長くかかります。
DeepSeek プロンプトの実践的 Tips
出力品質はプロンプトの書き方に大きく左右されます。よく機能するパターン:
リサーチノート・学習ガイド:
[トピック] を Markdown で要約してください:
- H2 の導入
- 3〜4 個の H3 サブセクション
- 数式があれば LaTeX で
- 末尾に「重要ポイント」の箇条書き
技術ドキュメント:
API ドキュメントを Markdown で書いてください:
- エンドポイントごとに H2
- ```bash と ```json のコード例
- パラメータ表(名前・型・必須・説明)
バイリンガル成果物:
プロジェクト提案書を Markdown で書いてください。並列の 2 セクションで出力:
最初に英語、次に 中文翻译。
各言語セクションに H2 を使用。
DeepSeek-R1 専用:
最終回答だけを Markdown で出力してください。
思考プロセスは含めないでください。
避けるべき落とし穴
- 「HTML を埋め込んだ Markdown」をリクエストしない。 Word コンバーターは純粋な Markdown を確実に処理しますが、Markdown と HTML が混在するとパーサが混乱します。
- 言語タグを省略しない。 タグなしの
```でも動きますが、シンタックスハイライトのメタデータが失われます。 - 3 階層を超える入れ子リストは避ける。 Word でも描画はされますが、見た目が窮屈です。
- セクション間に空行を入れる。 Markdown パーサはブロック境界を空行で識別します——空行がないと、見出しが前の段落に吸収されることがあります。
よくある質問
Q: DeepSeek-R1 の推論出力でもこのワークフローは動きますか?
A: 動きます。R1 の思考連鎖も Markdown なので、きれいに変換されます。最終回答だけが必要なら、プロンプトに 最終回答だけを Markdown で出力 と添えてください。思考プロセスは出力されません。
Q: DeepSeek の太字・斜体は保持されますか?
A: はい。Markdown の **bold** と *italic* は Word の太字・斜体スタイルに直接マップされます。
Q: DeepSeek が参照する画像は?
A: 現状 DeepSeek は画像を生成しませんが、 構文で画像 URL を参照すれば、コンバーターが Word に自動挿入します(URL が公開アクセス可能であれば)。
Q: ファイルサイズの制限は? A: 当ツールは最大 10 MB の Markdown を処理でき、書籍 1 冊分に相当する非常に長い文書もカバーします。それ以上のものはチャプター単位に分けて、Word でマージしてください。
Q: 繁体字中国語(繁體中文)にも対応していますか? A: 対応しています。プロンプトで「Traditional Chinese / 繁體中文」と指定してください。Word はシステムのデフォルト繁体字フォント(通常は PMingLiU や Microsoft JhengHei)で正しく描画します。
Q: DeepSeek のコンテンツはどうなりますか? A: あなたの Markdown は暗号化された接続で送信され、変換を実行するためだけに使われ、その直後に削除されます——恒久的に保存・閲覧・共有されることはありません。編集中のライブプレビューはあなたのブラウザ内で描画されます。
Q: 会社のブランドが入った Word ドキュメントにできますか? A: 変換後の Word ドキュメントは標準スタイル(Heading 1、Heading 2、Normal)を使います。Word の「スタイル」ペインで会社のテンプレートを適用すれば、ドキュメント全体をワンクリックでブランディングできます。
関連リソース
AI からドキュメントへのワークフローをさらに改善:
- ChatGPT から Word への完全エクスポートガイド — ChatGPT ユーザー向けの同じワークフロー
- ChatGPT Markdown 出力プロンプトの極意 — 変換しやすい出力を生むプロンプトパターン
- AI と LLM のための Markdown — Markdown が AI 出力の共通言語になった理由
- Markdown 変換のトラブルシューティング — テーブル・コード・画像の問題への対策
- Markdown の書き方入門 — Markdown 構文をゼロから
他の形式も:
- Markdown to PDF — 同じ忠実度で最終的な PDF を作成
- Markdown to HTML — Web 公開用コンテンツ
- ライブ Markdown エディタ — エクスポート前に DeepSeek 出力をプレビュー
まとめ
DeepSeek はフロンティア LLM の中でも特にクリーンな Markdown を生成し、特に数学・コード・バイリンガルコンテンツで強みを発揮します。この出力を Word に持ち込むコツは、明示的に Markdown をリクエストし、生のコードブロックをコピーし、LaTeX と CJK 文字を理解するツールで変換することです。
3 ステップのワークフロー:
- DeepSeek に Markdown をリクエスト
- 「Copy code」をクリック
- 数式と中国語をネイティブで扱えるツールで変換
数式は編集可能、中国語はくっきり、コードは読めるまま——DeepSeek セッションのたびに手作業で整形し直す必要はもうありません。
最初の DeepSeek 出力を変換しますか?無料コンバーターを開く →、Markdown を貼り付けるだけです。
役に立ちましたか?共有して広めましょう。