ChatGPTのMarkdown出力を使いこなす:必須プロンプトとコツ

ChatGPTに毎回きれいに整形されたコンテンツを返してほしいですか?鍵は、どうプロンプトを書くかにあります。このガイドでは、実用的なプロンプト技術を使って、ChatGPTに一貫性のある構造化されたMarkdown回答を生成させる方法を紹介します。
技術ドキュメントを書く開発者であれ、ブログ記事を執筆するコンテンツクリエイターであれ、ChatGPTのフォーマットを制御する方法を知っていれば、その出力ははるかに再利用しやすくなります。実用的なプロンプト、フォーマット技術、そしてその出力をプロフェッショナルなドキュメントに移す方法を取り上げます。
なぜChatGPTはデフォルトでMarkdownを生成するのか

ChatGPTがMarkdownに傾くのは単純な理由からです。Markdownは、HTMLの肥大化や独自フォーマットなしに、見出し、リスト、コードブロックといった構造を加える軽量マークアップ言語だからです。そのため、回答は生テキストとしても、レンダリングされた状態でも読みやすくなります。
その背景にあるもの
大規模言語モデルは膨大な量のテキストで訓練されており、技術コンテンツの多く — GitHubリポジトリ、ドキュメントサイト、開発者フォーラム — はMarkdownで書かれています。それだけ多くのMarkdownに触れたモデルは、特に技術的または説明的な回答において、自然とそれを生成する傾向があります。
実用的な利点もあります。Markdownは依存関係がありません。すでにMarkdownになっている出力は、追加処理なしでPandoc、静的サイトジェネレーター、Jupyterノートブックなどのツールにそのまま投入できます。
構造が役立つ理由
非構造化のプレーンテキストは、有用な部分を埋没させる密集した「文字の壁」のような回答になりがちです。Markdownは階層を加えます:
- セクションを区切る見出し
- リスト用の箇条書き
- スニペット用のフェンス付きコードブロック
その構造は、回答を拾い読みしやすく、バージョン管理で差分(diff)を取りやすくし、一般に場当たり的なフォーマットよりもスクリーンリーダーにとってアクセスしやすくします。すべてのモデルが同じようにフォーマットするわけではありません — 小規模または古いモデルは明示的なフォーマット指示が必要な場合がありますが、ChatGPTは多くの場合自分から構造を加えます。
ChatGPTのMarkdown出力を理解する

ChatGPTのMarkdownを最大限に活用するには、それが何をできて何をできないのかをおおよそ知っておくと役立ちます。構造化された回答を求めると、モデルは訓練中に学習したパターンに基づいて、見出し用の#やリスト用の-といった構文を挿入します。一般的な要素には信頼でき、エッジケースにはそれほどでもありません。
サポートされているMarkdown機能
ChatGPTはGitHub Flavored Markdown (GFM) のほとんどを扱います。GFMは、基本的なMarkdownを表、タスクリスト、取り消し線で拡張します。たとえば、次のように出力できます:
## Sample Heading
- Item 1
- Item 2 with **bold** text
| Column 1 | Column 2 |
|----------|----------|
| Data A | Data B |
```python
def hello():
print("World")
```
実用的な制限が一つあります。非常に長い、または複雑な表は長い回答の中で途切れることがあるため、生成する表はコンパクトに保つ価値があります。
回答における一般的な要素
ChatGPTはあなたの意図を構文にマッピングします。「ステップバイステップガイド」を求めると、通常は番号付きリストを返し、説明を求めると段落が返ってきます。太字(**text**)と斜体(*text*)は重要な用語を示します。
以下も扱います:
- 変数や短いスニペット用のインラインコード(
`code`) - 注釈用の引用ブロック(
> quote) [anchor](URL)形式のリンク
厳密でパーサーセーフなMarkdownが必要な場合、「strict Markdown」を明示的に求めると、不規則なエスケープのような小さな不整合が減ります。
プレーンテキスト vs Markdown
たとえばアルゴリズムについてのプレーンテキストの説明は、視覚的な区切りなしに何百語にもわたることがあり、追うのが難しくなります。同じ内容をMarkdownにすると、小見出しとリストを使って情報をチャンク化し、これは一般に可読性を向上させます。
この違いはツールにとっても重要です。Markdownの一貫したデリミタは、自由形式の散文よりもはるかに確実に解析・変換しやすくします。主な注意点は拡張機能のサポートです — GFMの表はうまく機能しますが、よりニッチな構文(脚注、カスタム絵文字)はどこでもレンダリングされるとは限りません。
一貫したMarkdown出力を得る方法

一貫したMarkdownは明確なプロンプトに行き着きます。フォーマット指示をプロンプトの早い段階に置き、回答全体を形作らせましょう。
シンプルな指示から始める
「Respond in Markdown format」のような基本的な指示はベースラインを設定します。たとえば:
プロンプト:「Explain REST APIs in Markdown format.」
典型的な出力:
# REST APIs Explained
REST (Representational State Transfer) is an architectural style for web services.
## Key Principles
- **Stateless**: Each request contains all the information needed.
- **Client-Server**: Separation of concerns.
「use headings and lists」を加えるとさらに精度が上がり、短い回答でもプレーンな段落ではなく構造化された形で返ってきます。
特定の機能向けに調整する
特定の要素を狙うには、具体的に指定します:
例:「Generate a Markdown table comparing Python frameworks, including links to the docs.」
これは、[Django](https://docs.djangoproject.com/) のようなアンカーリンク付きの表を返します。
複数パートの出力には、プロンプトを連鎖させます。まずコンテンツを求め、次にモデルにそれを再フォーマットさせます。役立つ習慣をいくつか挙げます:
- 表やタスクリストが必要なときは「GitHub Flavored Markdown」を指定する。
- 「make the lists bulleted.」のような短い修正で反復する。
- 長い回答がフォーマット途中で途切れないよう、個々のリクエストを適切な範囲に保つ。
Markdown出力のためのプロンプト例

以下は、基本から高度なものまで整理したプロンプトの例です。
基本的なプロンプト
日常的なタスクには、これらが素早くフォーマットされた出力を返します:
記事執筆
Write a short article on JavaScript closures in Markdown.
見出し、太字のキーワード、コードブロックを返します。
タスクリスト
Create a to-do list for deploying a Node.js app in Markdown with checkboxes.
GFMタスクリストを返します:- [ ] Install dependencies
要約
Summarize quantum computing basics in Markdown bullets.
拾い読みしやすい箇条書きリストを返します。
質疑応答
Answer: What is OAuth? Use Markdown headings.
回答を # Overview や ## Flow のような見出しの下に構造化します。
ブレインストーミング
List 5 blog ideas for AI ethics in Markdown.
クリーンで階層的なリストを返します。
高度なプロンプト
技術的な出力には、プロンプトを連鎖させて複雑さを積み上げます:
コードドキュメント:
First, write a Python sorting algorithm. Then format the explanation
in Markdown with fenced code blocks, a table for Big O complexity,
and a link to the CPython docs.
典型的な出力:
## Quicksort Implementation
```python
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
```
### Complexity Analysis
| Operation | Time Complexity | Space Complexity |
|-----------|-----------------|------------------|
| Best | O(n log n) | O(log n) |
| Average | O(n log n) | O(log n) |
| Worst | O(n²) | O(n) |
See [CPython sorting docs](https://docs.python.org/3/howto/sorting.html) for details.
数式付きデータ表:
Generate a Markdown table of ML model benchmarks,
and include LaTeX notation for any equations.
これはGFMをさらに押し広げます — $E = mc^2$ のようなインラインLaTeXは、変換すると数式としてレンダリングされます。
信頼できる出力のためのベストプラクティス
一貫した結果を得ることは、一般的なプロンプトエンジニアリングの助言と一致します。明確に、具体的に、そして反復することです。OpenAI とAnthropicはどちらも、これを頻繁に行うなら読む価値のあるプロンプトエンジニアリングガイドを公開しています。
セッション全体で一貫性を保つ
APIを使う場合、システムプロンプトがフォーマットを固定します:
You are a Markdown expert. Always respond in well-structured Markdown.
低めの温度設定(0.2〜0.5あたり)は変動を減らし、妥当な最大トークンの上限は回答がフォーマット途中で切れるのを防ぎます。Webインターフェースでは、指示を言い直すこと —「format the answer in Markdown」— が、長い会話がプレーンテキストに戻って漂流するのを防ぎます。
一貫性のない回答のトラブルシューティング
コードフェンスの欠落のような部分的なフォーマットは、通常あいまいなリクエストから生じます。いくつかの対処法:
- フェンスが欠けるときは「put all code in triple backticks」を付け加える。
- 長すぎるリストには「concise Markdown」を求める。
- 回答が複数の言語を混ぜる場合は「respond in English Markdown」を指定する。
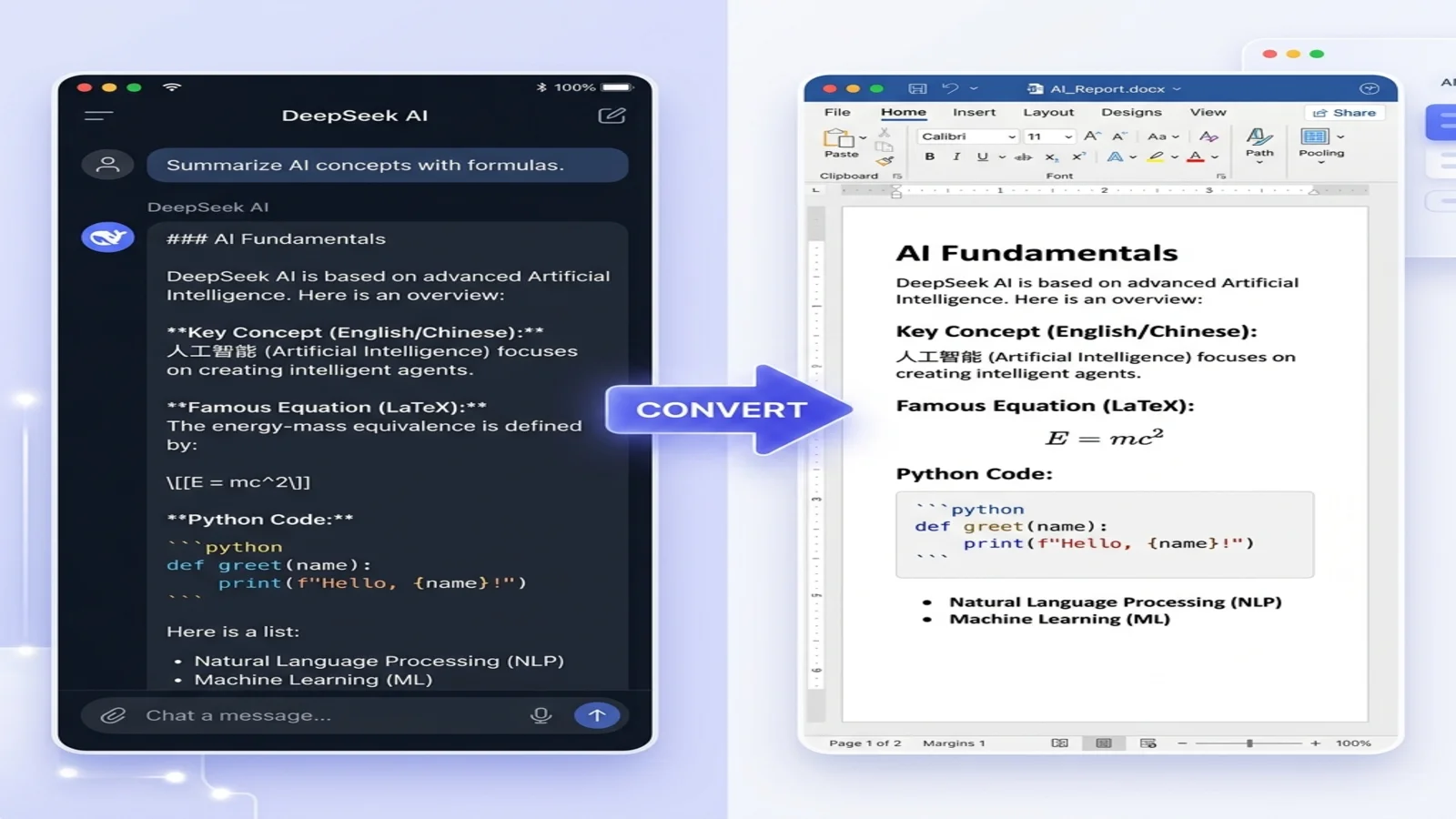
ChatGPTのMarkdownをWordに変換する
ChatGPTのMarkdownは優れた下書きになりますが、多くのチームはレビューと承認のためにWordドキュメントを必要とします。変換がそのギャップを埋めます。
なぜWordに変換するのか
Markdownは下書きとバージョン管理に向いており、Wordは変更履歴と慣れ親しんだスタイルでコラボレーションに向いています。GFMをサポートするコンバーターは、見出し、表、コードブロック、さらにはLaTeX数式までを手動の再フォーマットなしで .docx に移し — そしてWordはMarkdownの見出しから目次を自動生成できます。
構文そのものの入門については、Markdownの書き方 チュートリアルをご覧ください。
ステップバイステップの変換
- ChatGPTからMarkdown出力をコピーします。
- Markdown to Wordコンバーター を開きます。
- Markdownを貼り付けまたはアップロードします — GFMの表とコードブロックがサポートされています。
.docxをダウンロードします。太字、リンク、表はそのまま転送されます。- 最終編集のためにWordで開きます。
このプロセスはLaTeX数式を扱い、一般的なドキュメントなら数秒しかかかりません。
実世界の応用
ChatGPTのMarkdown出力は、最初の下書きから公開まで、コンテンツパイプラインに自然に収まります。
ブログ執筆ワークフロー
典型的な流れ:ChatGPTにプロンプトを出し —「draft a post on AI prompting in Markdown」— 構造化された下書きを得て、Markdown to Wordツール で変換し、Wordで仕上げ、そして公開します。利点は最初から一貫した構造があることで、再フォーマットにかける時間が減り、実際のコンテンツにより多くの時間をかけられます。一部のCMSエディターに生のMarkdownをそのまま貼り付けるとフォーマットが壊れるため、先に変換することでそれを回避できます。
技術ドキュメント
開発者向けガイドでは、ChatGPTはREADMEやAPIドキュメント用のMarkdownの骨格を、パラメータやベンチマーク用の表とともに生成できます。そこから、最終成果物用に MarkdownをPDFに変換 したり、Web公開用に MarkdownをHTMLに変換 したりできます。Markdownはモジュール式なので、後で1つのセクションを更新してもドキュメント全体を再フォーマットする必要はありません。
よくある落とし穴とその回避方法
ChatGPTのMarkdownは構造に強いものの、いくつかのプロンプトのミスが繰り返し見られます。
頻繁なプロンプトのエラー
- 過度な指定: Markdownにできないことを求める —「use blue links」「exactly 5 headings at 12pt」— と、一貫性のない結果につながります。構文がサポートするものに留めましょう。
- あいまいなリクエスト: 「List the pros and cons」はプレーンテキストを返すことがあります。「give me a Markdown table of pros and cons with columns X, Y, Z」は適切な表を返します。
- コードに言語タグがない: コードブロックにタグが付くよう、常に言語識別子を求めましょう(裸の
ではなくpython)。
長いプロンプトに頼る前に、短いプロンプトでプロトタイプを作り、反復してください。
Markdown vs 他のフォーマット
Markdownはすべての答えではありません。テキスト中心の物語的な出力に向いており、他のドキュメントフォーマットへきれいに変換されます。構造化データの交換にはJSONの方が適しており、インタラクティブなインターフェースには実際のUIコードが必要です。可読性、移植性、変換のしやすさといったその強みが実際に重要となる場面でMarkdownを選びましょう。
よくある質問
Q: Claudeや他のAIモデルでこれを使えますか?
A: はい。同じMarkdownプロンプトのアプローチは、テキストをフォーマットするあらゆるAIで機能します — 「output in Markdown format」と求めるだけです。
Q: 太字と斜体のフォーマットを保持するには?
A: Markdownは **bold**、*italic*、***bold italic*** を使い、ChatGPTはこれらをネイティブに生成し、対応するWordのフォーマットに変換されます。
Q: 数式についてはどうですか?
A: LaTeX表記を求めてください — たとえば「explain the quadratic formula using LaTeX in Markdown」 — するとChatGPTは $$\frac{-b \pm \sqrt{b^2-4ac}}{2a}$$ を返し、これは適切な数式に変換されます。
Q: 長さの制限はありますか?
A: ChatGPTのコンテキストウィンドウはモデルによって異なります。非常に長いドキュメントの場合は、セクションごとに作業し、後で結合してください。
Q: 表でも機能しますか?
A: はい。「a comparison table in Markdown format」を求めて列を指定すると、出力はGFM準拠できれいに変換されます。
関連リソース
- Markdown to Wordガイド: 完全な変換チュートリアル
- Markdown to PDF: 最終成果物用にPDFへ直接変換
- Markdown to HTML: Web対応のコンテンツを作成
- Markdownの書き方: 構文をゼロから学ぶ
結論
ChatGPTのMarkdown出力を制御することは、主に意図的にプロンプトを出すことに尽きます。Markdownを明示的に求め、必要な要素を指定し、結果がずれたら反復します。それを信頼できるコンバーターと組み合わせれば、モデルの出力はドキュメント、記事、レポートのための本物の初稿になります — 手作業で再フォーマットしなければならないものではなく。
実践する準備はできましたか?次のChatGPT回答で 無料のMarkdown to Wordコンバーター を試してみてください。
役に立ちましたか?共有して広めましょう。