Markdown für KI: Warum es für LLM-Workflows unverzichtbar ist

Wer sich mit KI-Werkzeugen beschäftigt, bemerkt schnell ein Muster: Prompts, Model Cards, Quelldokumente für Retrieval und Datensatz-Annotationen werden weitaus häufiger in Markdown geschrieben als in PDF oder Word. Das ist nicht nur eine Gewohnheit von Entwicklern. Markdowns Reintext-Struktur, semantische Klarheit und universelle Kompatibilität machen es zur natürlichen Schnittstelle zwischen menschenlesbaren Inhalten und maschinenverarbeitbaren Daten.
Dieser Leitfaden erklärt, warum Markdown sich für KI- und LLM-Inhalte gut eignet und wie Sie es für bessere Ergebnisse mit Sprachmodellen strukturieren.
Die Grundlagen verstehen
Die Stärke von Markdown liegt in seiner Einfachheit. Es wurde als leichtgewichtige Auszeichnungssprache entworfen, die in ihrer Rohform lesbar bleibt und sich sauber in HTML konvertieren lässt. Für KI-Anwendungen ist genau diese strukturierte Einfachheit der Grund, warum es so nützlich ist.
Warum Plain Text für Machine Learning wichtig ist
Im Gegensatz zu Binärformaten wie PDF oder DOCX ist eine Markdown-Datei reiner Text. Das hat reale Auswirkungen auf KI-Workflows:
- Direkte Verarbeitung: Markdown kann einem Sprachmodell ohne Extraktions- oder Vorverarbeitungsschritt zugeführt werden.
- Versionskontrolle: Git verarbeitet textbasierte Diffs sauber, was für kollaborative Datensätze und Prompt-Bibliotheken wichtig ist.
- Leichter Speicherplatz: Dasselbe Dokument ist als Markdown deutlich kleiner als als Word- oder PDF-Datei.
- Universelle Kompatibilität: Jedes System und jedes Tool kann es lesen.
Für Trainings- und Retrieval-Pipelines beseitigt diese Einfachheit eine ganze Klasse von Problemen – keine proprietären Parser, keine Extraktionsfehler aus gescannten PDFs.
Semantische Struktur
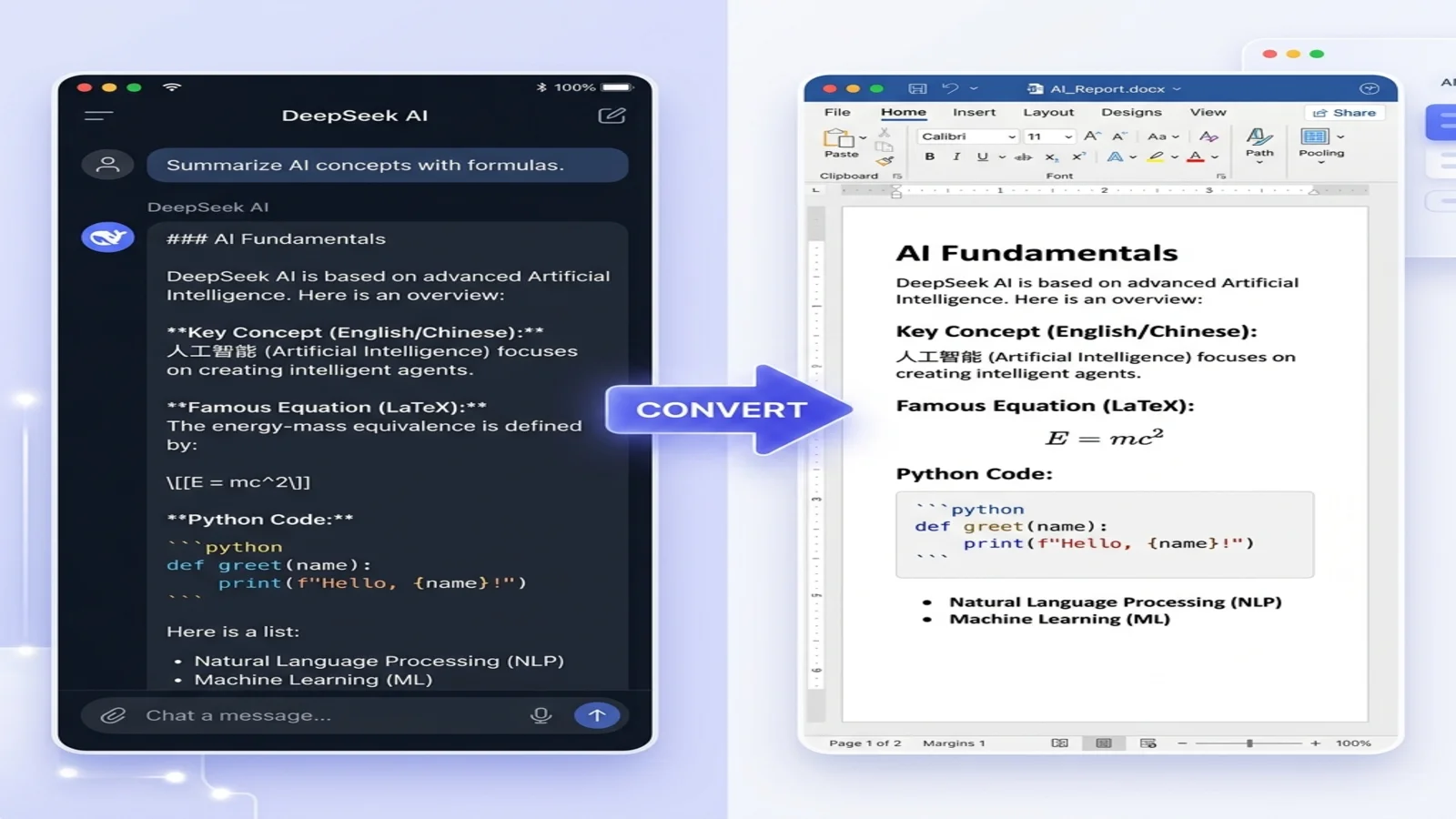
Was Markdown für KI auszeichnet, sind seine semantischen Elemente. Überschriften (#, ##, ###) schaffen eine klare Hierarchie, Listen gruppieren zusammengehörige Elemente und Code-Blöcke isolieren technische Inhalte. Das sind strukturelle Signale, nicht bloß visuelle Formatierung.
Betrachten Sie dieses Beispiel:
## Training Configuration
- Model: transformer-based
- Dataset size: 10M tokens
- Batch size: 32
### Hyperparameters
| Parameter | Value |
|-----------|-------|
| Learning rate | 0.001 |
| Epochs | 50 |
Die Überschriften markieren Themengrenzen, die Liste präsentiert sequentielle Informationen und die Tabelle enthält strukturierte Daten. Ein Modell, das dies liest, erhält explizite Hinweise darauf, wie der Inhalt organisiert ist, statt die Struktur allein aus der Prosa ableiten zu müssen.
Wie Sprachmodelle strukturierte Inhalte verarbeiten

Sprachmodelle zerlegen Text in Token, bevor sie ihn verarbeiten. Markdowns Trennzeichen – Sternchen für Betonung, Rauten für Überschriften, Backticks für Code – sind konsistente, vorhersagbare Marker innerhalb dieses Token-Stroms.
Struktur als Signal
Eine Überschrift wie ## Hyperparameters ist ein klarer, konsistenter Marker dafür, dass ein neuer Abschnitt beginnt. Leitfäden zum Prompt Engineering großer Modellanbieter – sowohl von OpenAI als auch von Anthropic – empfehlen, Modellen klar abgegrenzte, gut strukturierte Eingaben zu geben. Markdown ist eine unkomplizierte Möglichkeit, genau das zu tun.
In der Praxis hilft gut strukturierte Eingabe tendenziell bei:
- Beim Thema bleiben: Klare Abschnitte erleichtern es einem Modell, seine Antwort thematisch einzugrenzen.
- Kontexterhaltung: Überschriften fungieren in langen Dokumenten als Anker.
- Anweisungen befolgen: Die Trennung von „Kontext“ und „Anforderungen“ reduziert Mehrdeutigkeit.
Das sind Tendenzen, keine Garantien – Struktur hilft, ersetzt aber keinen gut formulierten Prompt.
Hierarchie und Attention
Transformer-Modelle gewichten, welche Teile der Eingabe für die Aufgabe am relevantesten sind. Eine konsistente Hierarchie H1 → H2 → H3 liefert diesem Prozess eine klarere Landkarte des Dokuments als eine undifferenzierte Textwand.
Formate im Vergleich

Markdown ist nicht für jede Aufgabe die richtige Wahl, aber für KI-Workflows hat es klare Vorteile gegenüber traditionellen Dokumentformaten. Die folgende Tabelle fasst die allgemeinen Kompromisse zusammen:
| Format | Bearbeitbarkeit | Token-Effizienz | Versionskontrolle | Eignung für KI-Verarbeitung |
|---|---|---|---|---|
| Markdown | Hoch | Hoch | Nativ (Reintext) | Direkt |
| Niedrig | Niedrig | Schwierig | Extraktion nötig | |
| DOCX | Mittel | Niedrig | Schwierig (binär) | Extraktion nötig |
| HTML | Mittel | Mittel | Praktikabel | Direkt, aber ausführlich |
Der Kernpunkt ist Zuverlässigkeit. Binärformate benötigen einen Extraktionsschritt, und genau dieser Schritt ist die Stelle, an der sich Parsing-Fehler einschleichen – Fehler, die Trainingsdaten beschädigen oder einem Modell verstümmelte Eingaben liefern können.
Kompromisse
Markdown hat durchaus Grenzen: keine native Unterstützung für komplexe Layouts, eingebettete Medien erfordern externe Dateien, und die Gestaltungsmöglichkeiten sind minimal. Für KI-Arbeit ist dieser Minimalismus meist ein Vorteil – der Inhalt bleibt auf die Substanz fokussiert. Wenn Sie ein poliertes Ergebnis benötigen, können Sie mit einem Tool wie unserem Markdown-zu-Word-Konverter in Markdown entwerfen und in ein professionelles Format exportieren.
Praktische Markdown-Funktionen für KI-Inhalte

Einige Markdown-Funktionen sind beim Arbeiten mit Sprachmodellen besonders nützlich.
Tabellen für strukturierte Daten
Eine Markdown-Tabelle präsentiert tabellarische Informationen in einer Form, über die ein Modell direkt urteilen kann:
| Model | Context window | Structured input |
|-------|----------------|-------------------|
| Example A | Large | Handled well |
| Example B | Very large | Handled well |
Das ist klarer, als dieselben Daten in Prosa zu beschreiben – ein Modell kann bestimmte Werte extrahieren und Zeilen vergleichen. Halten Sie Tabellen angemessen kurz, damit sie das Kontextfenster nicht dominieren.
Code-Blöcke für technische Inhalte
Eingezäunte Code-Blöcke isolieren Code vom umgebenden Text:
```python
def train_model(data, epochs=50):
# Training logic here
return model
```
Die Einzäunung mit drei Backticks verhindert, dass das Modell Code-Interpunktion als Erzähltext fehlinterpretiert – wichtig beim Generieren von Code oder Dokumentieren von APIs.
Listen für sequentielle Informationen
Geordnete und ungeordnete Listen signalisieren unterschiedliche Beziehungen:
- Ungeordnete Listen (
-oder*) für Mengen von Konzepten oder Features - Geordnete Listen (
1.,2.) für Schritte, die in einer Reihenfolge ablaufen
Den Listentyp dem Inhalt anzupassen hilft einem Modell, Anweisungen in der vorgesehenen Reihenfolge zu befolgen.
Markdown in einem KI-Workflow einsetzen

Datensatz-Vorbereitung
Annotationsdaten von Anfang an in Markdown zu strukturieren hält sie lesbar und bearbeitbar:
- Verwenden Sie Überschriften, um Kategorien oder Beispiele zu trennen.
- Verwenden Sie Listen für Multi-Turn-Konversationen oder sequentielle Daten.
- Halten Sie verborgenen Kontext in HTML-Kommentaren (
<!-- key: value -->), wenn Sie Metadaten benötigen, die nicht im sichtbaren Text erscheinen sollen.
Für viele Annotationsaufgaben lässt sich das leichter schreiben und prüfen als reines JSON oder CSV.
Prompt Engineering
Markdown verleiht Prompt-Templates eine klare Form:
## Task: Summarize the following article
### Context
[Article text here]
### Requirements
- Length: 3-5 sentences
- Focus on key findings
- Maintain an objective tone
Aufgabe, Kontext und Anforderungen in beschriftete Abschnitte zu trennen, macht die Anweisungen für ein Modell leichter zu parsen.
Dokumentation und Model Cards
Markdown ist der Standard für Modelldokumentation – Hugging Face Model Cards sind darin geschrieben. Es ermöglicht, Spezifikationen in Tabellen, Beispiele in Code-Blöcken, erklärende Prosa und Zitate als Links zu kombinieren – alles in einer einzigen Git-freundlichen Quelldatei.
Optimierungstipps

Überschriftenebenen konsistent halten
Verwenden Sie Überschriften progressiv – springen Sie nicht von H1 zu H3. Eine konsistente Hierarchie hält die Struktur des Dokuments eindeutig. Ein Linter wie markdownlint kann dies in einer CI-Pipeline automatisch durchsetzen.
Sonderzeichen maskieren
Maskieren Sie Zeichen, die sonst als Syntax interpretiert würden:
Use `\*` to display an asterisk literally
So vermeiden Sie Fälle, in denen ein Modell – oder ein nachgelagerter Parser – das Symbol falsch liest.
Das Kontextfenster verwalten
LLMs haben Token-Limits. Halten Sie Markdown-Dokumente modular: Teilen Sie lange Dateien in Abschnitte auf, die unabhängig verarbeitet werden können, statt sich auf eine einzige überdimensionierte Datei zu verlassen.
Häufige Fallstricke vermeiden
Auf ein paar wiederkehrende Fehler lohnt es sich zu achten:
- Inkonsistente Leerzeichen: Das Mischen von Tabs und Leerzeichen kann manche Parser stören.
- Zu starke Verschachtelung: Listen, die mehr als drei oder vier Ebenen tief sind, werden schwer nachvollziehbar – für Modelle wie für Menschen.
- Nicht maskierte Zeichen: Validieren Sie Code-Blöcke, damit verirrte Symbole den Parse nicht verändern.
- Flavor-Inkompatibilitäten: Bleiben Sie bei einer breit unterstützten Variante – die CommonMark-Spezifikation und GitHub Flavored Markdown sind die sichersten Grundlagen.
Ein Test mit einigen Beispieleingaben vor einem großen Durchlauf fängt die meisten dieser Probleme früh ab.
Wohin sich Markdown entwickelt

Markdown nimmt fortlaufend die Anforderungen der KI-Arbeit auf. Die Mermaid-Syntax stellt Diagramme als Text dar, und YAML-Frontmatter trägt Metadaten, ohne den Textkörper zu überladen. Beides hält Dokumente in einer einzigen Reintext-Datei, die diff-bar und leicht verarbeitbar bleibt.
Wann etwas anderes besser ist
Markdown ist nicht immer die Antwort. Stark visuelle Inhalte sind möglicherweise als HTML besser aufgehoben. Strukturierter Datenaustausch ist meist als JSON besser. Und für ein finales Ergebnis, das präzise Formatierung erfordert, konvertieren Sie zu Word oder PDF – unser kostenloser Konverter übernimmt diesen Schritt.
Nutzen Sie Markdown dort, wo es wirklich glänzt: Entwurf, Kollaboration, Versionskontrolle und das Zuführen strukturierter Inhalte an Sprachmodelle.
Erste Schritte
Wenn Markdown noch nicht Teil Ihres KI-Workflows ist, fangen Sie klein an:
- Schreiben Sie Ihr nächstes Prompt-Template in Markdown statt in reinem Text.
- Strukturieren Sie einen kleinen Datensatz mit Überschriften und Listen.
- Lassen Sie ihn durch Ihr gewohntes Modell laufen und vergleichen Sie die Ergebnisse mit einer unstrukturierten Version.
Sobald Sie sich sicher fühlen, ergänzen Sie Tabellen, Code-Blöcke und Metadaten dort, wo sie helfen.
Für Teams, die sich von traditionellen Formaten lösen, funktioniert ein hybrider Ansatz gut: in Markdown entwerfen für Geschwindigkeit und Kollaboration, dann für die Auslieferung in ein poliertes Format konvertieren. Unser Blog bietet weitere Tutorials zu diesem Workflow.
Fazit
Die Beliebtheit von Markdown in KI und Machine Learning ergibt sich aus praktischen Vorteilen, die sich über den gesamten Entwicklungszyklus summieren: Reintext-Einfachheit, semantische Struktur und universelle Kompatibilität. Für Trainingsdaten, Prompt-Templates und Modelldokumentation ist es ein zuverlässiges, reibungsarmes Format.
Die Lernkurve ist gering. Strukturieren Sie ein Projekt in Markdown, vergleichen Sie es mit Ihrem aktuellen Ansatz und lassen Sie die Ergebnisse entscheiden.
Finden Sie dieses Tool nützlich? Helfen Sie uns, es zu verbreiten.